
Powoli wracamy do świata żywych (i pracujących) i przygotowujemy kolejne teksty na bloga. W międzyczasie zapraszamy do kolejnego #maina z lekko historyczną notką biograficzną!
Cykl #main to punkt początkowy Waszego tygodnia, prasówka, w której zbieramy ciekawe linki, dzielimy się informacjami, a także podsyłamy programistyczne zadanie. Mamy nadzieję, że w ten sposób umilimy Wam poniedziałkowy powrót do rzeczywistości ;)
Nowy obraz Rembrandta
Ostatnio w sieci pojawił się ciekawy przykład zastosowania Machine Learningu i technik 3D — opracowano algorytm, który ‘uczy się’, jak malowali mistrzowie, a następnie odtwarza ich technikę tworząc nowe dzieła. Nie są to jednak kopie istniejących — algorytm ten poza technicznymi aspektami (sposób kładzenia farby, styl obrazu itp) uczy się także stylu danego malarza (co malował najczęściej, w jakiej perspektywie ) i na tej podstawie generuje zupełnie nowe dzieło od podstaw. W przypadku Rembrandta uznał, że kolejnym dziełem powinien być biały człowiek w wieku 30–40 lat, z brodą i w kapeluszu. Następnie wydrukowano je na drukarce 3D tak, aby efekt przypominał oryginalne malunki.
Podobno ‘fałszerstwo’ to jest bardzo trudne do wykrycia przez osobę nie będącą ekspertem na temat twórczości danego malarza.
Więcej w artykule w serwisie NEXT.
HTC Vive
Rzeczywistość wirtualna to od czasu premiery firmy Oculus gorący temat — i słusznie, bo możliwości są ogromne, od gier i rozrywki, poprzez wizualizacje danych i e‑learning, na realistycznych wideokonferencjach kończąc. I o ile pierwszy raz o Oculus Rift usłyszeliśmy rok temu i dopiero od niedawna można składać zamówienia (będą realizowane w sierpniu), o tyle HTC postanowiło zrobić rewolucję. HTC Vive to nie tylko okulary VR — to cały system, wraz z urządzeniami wskazującymi i pozycjonującymi w przestrzeni. Innymi słowy — kompletny system do różnych zastosowań. Przy cenie 899 EUR i dostępności już w czerwcu, może być sporą konkurencją dla Oculusa (same okulary w cenie 599$). Jedyny minus — aby w pełni z niego korzystać (w bezpieczny sposób) potrzeba sporo przestrzeni.
Oficjalna strona
Filmik z prezentacją działania w serwisie cnet.
Nauka programowania z Billem Gatesem
Na kanale Code.org pojawiły się filmy, w których znane osoby, jak Bill Gates czy Mark Zuckerberg uczą podstawowych koncepcji związanych z programowaniem — polecamy dla osób zaczynających naukę lub jako zachętę dla znajomych rozważających czy nie nauczyć się programować ;)
Jeden z filmów — Bill Gates o konstrukcji ‘if’ i pętlach
Wszystkie filmy z tej serii
Vivaldi
Z przeglądarkami jest trochę jak z telefonami komórkowymi — na początku dostajemy wydajne rozwiązanie, które po kilku miesiącach zamienia się w ‘słonia’. Swego rodzaju rewolucję zaproponował Chrome, który jednak ma coraz więcej funkcji i jest przez to coraz bardziej zasobożerny. Ostatnio pojawiła się nowa alternatywa — przeglądarka Vivaldi. Z założenia ma ona być szybką, minimalistyczną przeglądarką, którą w prosty sposób można dostosować do swoich potrzeb (wygląd, układ okna itp). Jest tworzona w dużej mierze przez osoby wcześniej związane z Operą. Ma też kilka ‘bonusów’, które uprzyjemniają pracę, np. kolor okna dopasowuje się do kolorystyki aktualnej strony (co daje zaskakująco przyjemny efekt), ale co najważniejsze — bazuje na silniku Chromium (open-sourceowa część przeglądarki Chrome, która zawiera głównie silnik renderowania stron), przez co jest w 100% zgodna z dodatkami dla przeglądarki Google Chrome (i można je bez problemu instalować). Póki co nasze wrażenia są pozytywne, zobaczymy za jakiś czas czy tym razem przeglądarka dotrzyma słowa!
Strona główna przeglądarki Vivaldi
Artykuł z recenzją w serwisie techspot.com
Odpowiedź na pytanie z zeszłego tygodnia
A pytaliśmy o to: Jak wygląda trójwarstwowy podział aplikacji w praktyce?
O trójwarstwowym podziale aplikacji pisaliśmy już w lekcji #14.1 dotyczącej serwisów, tą odpowiedź można traktować jako uzupełnienie tamtej wiedzy.
W standardowym podejściu wyróżniamy trzy warstwy aplikacji (wraz z ich funkcjami):
- Warstwę kontrolerów / serwisów REST
- zapewnia interfejs do komunikowania się z systemem przez użytkowników lub inne systemy
- dokonuje walidacji danych przychodzących
- jest odpowiedzialny za uwierzytelnianie, może być częściowo odpowiedzialna za autoryzację
- obsługuje błędy z punktu widzenia użytkownika — np. zamienia wyjątki na przyjazne uzytkownikowi komunikaty
- konwertuje obiekty z domeny zewnętrznej (DTO, API) na wewnętrzną
- Warstwę logiki biznesowej / serwisów wewnętrznych
- realizuje logikę biznesową (funkcjonalność systemu)
- dostarcza obsługi wyjątków (np. logikę związaną z powtórzeniem operacji czy anulowaniem jej efektów)
- integruje aplikację z innymi systemami, obsługuje błędy związane z integracją itp
- Warstwę persystencji / źródło danych
- konwertuje wewnętrzną domenę na obiekty specyficzne dla sposobu zapisu danych, z jakiego korzystamy
- utrwala dane lub je odczytuje, konweruje wyjątki na taki, które są wykorzystywane w aplikacji
Poniższa grafika obrazuje jak to działa — ‘Warstwa’ to zbiór wszystkich obiektów (np. serwisów, kontrolerów) w danej warstwie, a ‘Model’ to obiekty domenowe i ich ‘zasięg’ (obrazowe przedstawienie, gdzie są wykorzystywane).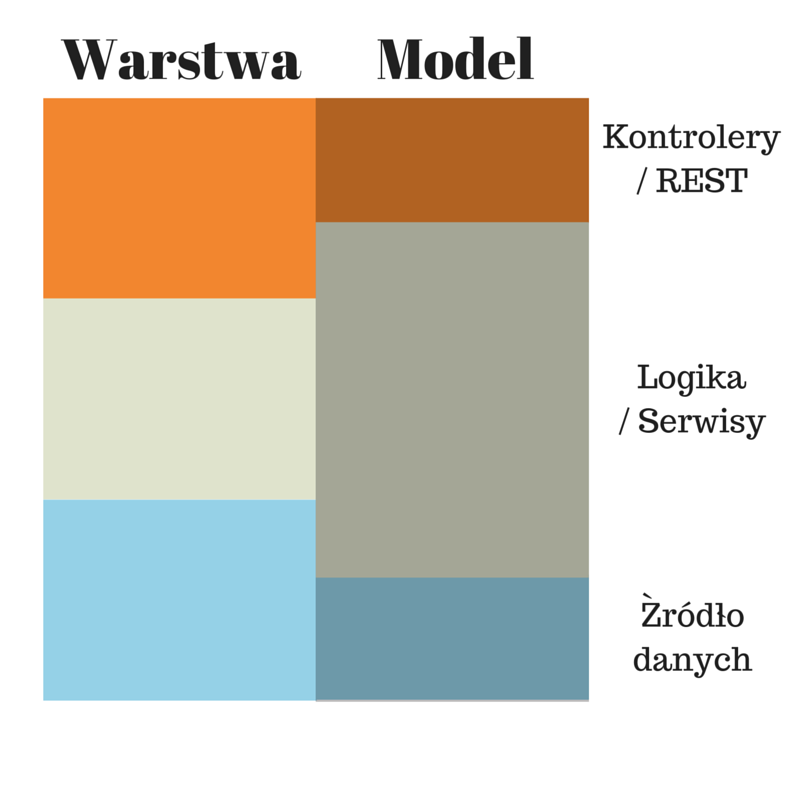
Wynika z tego kilka podstawowych zasad, przestrzegając których znacznie uprościsz sobie życie w przyszłości:
- warstwy komunikują się tylko ‘w dół’ i tylko bezpośrednio
- NIGDY domena wewnętrzna nie może być używana w zewnętrznych interfejsach systemu, podobnie jak nie może być używana zapisując dane
- jeśli jest potrzeba udostepnienia dokładnie takich samych informacji na zewnątrz lub utrwalenie informacji nie wymaga żadnych zmian tego obiektu, i tak warto utworzyć dokładnie identyczny obiekt i ‘przepisywać’ dane w odpowiedniej warstwie
- interfejsy warstwy logiki biznesowej i warstwy persystencji używają wewnętrznej domeny
- oznacza to, że warstwy skrajne muszą dokonywać konwersji pomiędzy domenami, i jest to ich odpowiedzialność
- poza warstwą serwisów (i w wyjątkowych przypadkach persystencji), komunikacja pomiędzy różnymi komponentami danej warstwy (np. dwoma kontrolerami czy dwoma DAO) nie powinna istnieć w aplikacji
Choć czasem nie jest to łatwe, a niekiedy aż prosi się o pójście na skróty, dzięki stosowaniu się do tych zasad dostajemy kilka ważnych korzyści:
- zmiana technologii przechowywania danych nie wpływa na reszte aplikacji i jest ‘przezroczysta’
- obiekty domenowe (wewnętrzny model) pozbawione są adnotacji/logiki związanych z zapisywaniem danych i ich walidacją czy przesyłaniem poza system
- mając działającą aplikację możemy stworzyć do niej dodatkowe API czy interfejs, nie wpływając na istniejące elementy
- jeśli w aplikacji jest problem, wiadomo gdzie go szukać w kodzie
- użytkownik przypadkowo nie uzyska dostępu do wewnętrznych informacji (np. używając wewnętrznego obiektu ‘user’ moglibyśmy udostępnić na zewnątrz hasło czy inne wrażliwe dane)
- interfejs aplikacji (lub jej zewnętrzne API) może być zorganizowane inaczej, niż aplikacja wewnętrznie
Oczywiście to jedna z wielu koncepcji budowy aplikacji (choć najpopularniejsza i najbardziej uniwersalna). W przyszłości przybliżymy inne opcje i ich wady/zalety.
Więcej pytań technicznych z poprzednich mainów wraz z linkami do odpowiedzi znajdziesz tutaj!
James L. Buie
Bohaterem tej edycji #main jest mniej znana postać, która jednak znacząco wpłynęła na współczesną branżę IT. Mowa o Jamesie Buie, wynalazcy logiki TTL.
James był weteranem II wojny światowej, po wojnie zatrudnił się w laboratoriach TRW (obecnie Northrop Grumman) gdzie zajmował się elektroniką i elektrotechniką, głównie na użytek wojska. Jego najbardziej znanym odkryciem z 1961 roku jest TTL (ang. Transistor — Transistor Logic), która to do dzisiaj używana jest do produkcji układów scalonych i komputerów. Odkrycie to miało fundamentalne znaczenie, ponieważ wcześniej używane technologie (RTL, DTL) korzystały z różnego rodzaju komponentów do budowy bramek logicznych — z tego powodu były one duże (fizycznie), i ich rozmiar ograniczał możliwości zastosowania i zwiększał koszt produkcji. TTL to w uproszczeniu sposób na budowę bramek logicznych (czyli elektronicznych odpowiedników operacji ’ | ‘, ’ & ’ i podobnych znanych z języków programowania) używający wyłącznie tranzystorów. To pozwoliło na budowę pierwszych układów scalonych z prawdziwego zdarzenia (patent na układy scalone pochodzi z 1949 roku) — ówcześnie zastosowanych oczywiście najpierw w rakietach i innego rodzaju broni. Co ciekawe, seria układów która powstała w tamtym czasie (74xx, seryjnie produkowane od 1964 roku) do dziś jest jednym z popularniejszych elementów wśród elektroników-amatorów (i nie tylko).
Pracę w TRW kontynuował do swojej emerytury w 1983 roku, skupiając się przede wszystkim na układach scalonych i systemach zintegrowanych. W tej dziedzinie posiada też kilka innych patentów, m.in. na konstrukcję układów mnożących jak też sposób przekształcania ‘wafla’ na układy scalone.
