
Dzisiaj nauczysz się korzystać z Gita — systemu kontroli wersji, który stał się de facto standardem na rynku.Git to rozproszony system kontroli wersji (co to dokładnie znaczy, powiemy sobie za moment), u którego podstaw leżą bardzo proste założenia. To jest jednak jego potęgą — elastyczność oraz kilka sprytnych pomysłów spowodowała że powstało narzędzie proste w użyciu, pasujące zarówno do prostych projektów jak i ogromnych przedsięwzięć (jak np. jądro systemu linux).
Git jest praktycznie wymaganą kompetencją w wielu firmach i od tego momentu rozwiązania naszych lekcji oraz dodatkowe materiały będziemy publikować właśnie w ten sposób.
Podstawowe pojęcia
Zanim przejdziemy do meritum, wyjaśnijmy podstawowe pojęcia i skróty, których będziemy używać.
- SCM — to akronim od Source Code Management, czyli dosłownie kontrola kodu (w języku polskim funkcjonuje określenie system kontroli wersji); jest to system który pozwala na archiwizowanie i śledzenie zmian w kodzie, dzięki czemu możemy cofać się w historii lub podejrzeć, kto był autorem konkretnej zmiany
- Repozytorium — ‘kontener’ na określony zbiór kodu, najczęściej jeden projekt; repozytorium pozwala grupować kod i zmiany, dzięki czemu możemy przeglądać wszystkie zmiany wykonane w ramach jednego repozytorium, przyznawać uprawnienia do repozytoriów oraz pobierać / kopiować je
- Commit (lub rewizja) — jest to proces ‘wysłania’ na repozytorium określonych zmian w kodzie — jeśli pobierasz kod z repozytorium, następnie dokonujesz modyfikacji i wysyłasz te zmiany z powrotem do repozytorium, proces ten nosi nazwę commitowania, a same zmiany wysłane razem nazywamy commitem lub rewizją
- pull / push — odpowiednio pobranie i wysłanie zmian (jednego lub wielu commitów) z/do innego repozytorium
- diff — (ang. różnica) — jest to różnica pomiędzy różnymi rewizjami — dzięki temu możemy zobaczyć, które fragmenty uległy zmianie oraz w jaki sposób; pozwala to także zoptymalizować transfer danych pomiędzy repozytoriami
- fork — kopia repozytorium; szczególnie popularne w przypadku projektów open-source, dzięki czemu możemy skopiować cały projekt i rozwijać go niezależnie (np. dopasowując do naszych potrzeb)
- branch — odgałęzienie, wersja wewnątrz repozytorium; branche pozwalają na prace wielu osobom równocześnie, bez ciągłego wchodzenia sobie w drogę i nadpisywania zmian — każdy może pracować na swoim branchu, dopiero po zakończeniu pracy łącząc zmiany z innymi i rozwiązując problemy
- merge — połączenie wielu zmian z różnych źródeł, które może skutkować niekompatybilnymi zmianami wymagającymi ręcznych modyfikacji; merge pozwala łączyć prace wykonywane w różnych obszarach, które mogą się zazębiać, w jedną całość w sposób kontrolowany i świadomy
Tyle definicji — na ten moment mogą one brzmieć abstrakcyjnie, ale już za chwile wytłumaczymy sobie o co dokładnie chodzi.
Klient Git
Podczas tego tutorialu będziemy korzystać z graficznego klienta Git o nazwie Smart Git — jest on bezpłatny do użytku prywatnego, i spośród przetestowanych przez nas rozwiązań spisał się najlepiej. Oboje używamy go w pracy i prywatnie :) Oczywiście Gita można używać także z konsoli lub za pomocą bibliotek takich jak JGit — na początek polecamy jednak coś prostszego ;)
Dlaczego SmartGit? Z kilku powodów, przede wszystkim nigdy nas nie zawiódł (niedziałająca funkcjonalność, reklamy, blokowane funkcje, brak aktualizacji itp). Jego interfejs jest przejrzysty, etykiety przycisków nawiązują do poleceń git, które wykonują (co jest bardzo pomocne, jeśli szukasz jak zrobić coś w gicie ogólnie — możesz to łatwo przenieść do klienta), a graficzne kontrolki (np. historia, czy różnice pomiędzy wersjami) są czytelne, jasne i przyjazne. Dodatkowo działa na każdym systemie, z którego musimy lub chcemy korzystać. Wady to oczywiście konieczność kupienia licencji, aby używać w wersji komercyjnej — z drugiej strony cena zdecydowanie nie jest wygórowana i w naszej opinii produkt wart jest swojej ceny. Licencja jest też dla developera, a nie instalacji — dzięki temu jednej licencji możesz używać w pracy i w domu. Program ten integruje się także z GitHub’em, co także będzie pomocne.
Inne aplikacje
Oczywiście istnieje mnóstwo innych, mniej lub bardziej rozbudowanych klientów GIT. Pomimo, że ten mini-kurs opiera się o SmartGit, prawie wszystkie programy oferują tą samą funkcjonalność — układ okien może być inny, nazwa funkcji w menu, ale możliwości pozostają te same. Podobnie jak ze środowiskiem IDE — jedyny słuszny wybór to taki, który jest dla Ciebie wygodny i przyjemny w użyciu. Na oficjalnej stronie Git’a znajdziesz linki do różnych klientów — komercyjnych oraz nie. Wybierając klienta pomyśl też o swojej pracy — o ile nie wykupisz licencji komercyjnej lub licencja bezpośrednio na to nie zezwala, najprawdopodobniej programu nie będziesz mogła używać w firmie. To ważne pod kątem przyzwyczajania się do narzędzia i ‘intuicyjnej’ obsługi.
Miej też na uwadze, że zarówno Eclipse jak i IntelliJ IDEA posiada funkcjonalności związane z obsługą Git — niektórzy developerzy korzystają tylko z nich, dla nas zewnętrza aplikacja okazała się wygodniejsza w użyciu i oboje korzystamy z klientów graficznych poza IDE.
Hosting repozytorium Git
W tym wypadku skorzystamy z platformy GitHub — jednej z pierwszych i zdecydowanie najpopularniejszej. Można w niej bezpłatnie założyć konto oraz — o ile nie chcemy ukryć naszego repozytorium — można także bezpłatnie przechowywać tam swoje projekty.
Pamiętaj tylko, że Twój profil na GitHub to także Twoja wizytówka jako programisty — o ile nie ukryjesz repozytorium, każdy może je znaleźć i obejrzeć. Jest to jedna z lepszych form weryfikacji kompetencji przez potencjalnych pracodawców — dlatego pamiętaj aby utrzymywać tam porządek i wysyłać kod, którego się nie powstydzisz :) Oczywiście wszystko można później poprawić, o ile się o tym pamięta ;)
Inne opcje
Na rynku istnieje masa alternatyw, zarówno bezpłatnych jak i płatnych, ale to GitHub jest platformą często wybieraną przez firmy, oraz do tej pory najstabilniejszą. Ponadto nie próbuje być ‘platformą do wszystkiego’ dzięki czemu interfejs jest przejrzysty i nie gubi. Szczególnie podczas nauki jest to ważne, aby narzędzia pomagały ćwiczyć zdobytą wiedzę, a nie stanowiły łamigłówek do rozwiązywania za każdym razem.
Jeśli jesteś ciekawa innych platform, sprawdź np. bitbucket.org czy gitlab.com
Zanim zaczniemy
Przed rozpoczęciem pracy upewnij się, że masz zainstalowanego klienta Git (np. wspomniany wyżej Smart Git) oraz masz założone konto w repozytorium, np. GitHub (choć nie jest to stricte konieczne, zalecamy abyś posiadała konto w celu przetestowania wszystkich podstawowych opcji).
Jeśli obie rzeczy masz gotowe, to zaczynamy!
Tworzenie nowego repozytorium
Tą lekcje zaczniemy od utworzenia nowego repozytorium. Repozytorium to miejsce, w którym będzie przechowywany Twój kod.
Git jako narzędzie jest zdecentralizowany, co oznacza że nie ma ‘centralnego’ repozytorium z definicji, a jedynie powiązane ze sobą, ale zarządzane oddzielnie repozytoria. Oznacza to tyle, że na Twoim komputerze także będzie pełnoprawne repozytorium Git (które ktoś może w teorii używać tak jak Ty użyjesz GitHub’a), ale będzie ono zawierało informację o tzw. upstream repository — czyli repozytorium ‘nadrzędnym’, w naszym przypadku będzie to po prostu utworzone na GitHubie. O ile Git pozwala tego nie wymaga, większość developerów pracuje z nim tak, jakby był to system centralny — jedno repozytorium w serwisie GitHub czy podobnym służy za wspólne miejsce dla wszystkich programistów, z którego pobierają zmiany innych i wysyłają swoje zmiany.
W sytuacji kiedy mamy repozytorium nadrzędne, pierwszym krokiem jest utworzenie nowego repozytorium nadrzędnego, na serwerach zdalnych.
Tworzenie repozytorium w serwisie GitHub
Po zalogowaniu w serwisie GitHub.com przyciski u góry pozwalają łatwo przejść do opisu istotnych elementów aplikacji. Zachęcamy do zapoznania się z tymi materiałami, znajdziesz tam wiele ciekawych wskazówek i porad jak korzystać w sposób efektywny.
Aby utworzyć repozytorium, w prawym górnym rogu wybieramy opcję ‘New repository’ z menu rozwijanego.
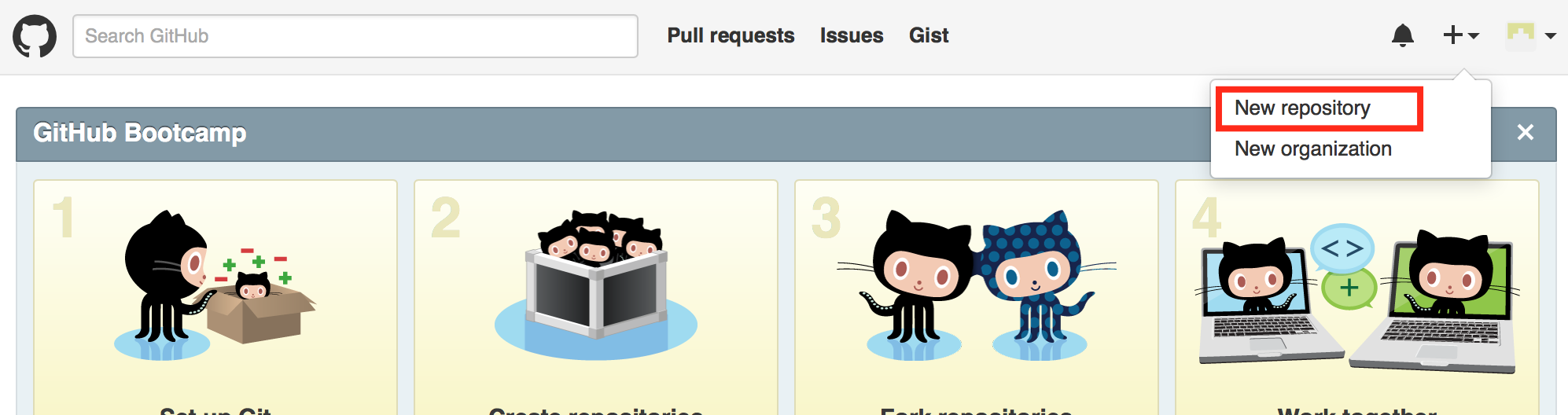
Tworzenie nowego repozytorium w serwisie GitHub.com
Pojawi się okno, w którym musimy wybrać nazwę naszego repozytorium oraz możemy określić kilka dodatkowych parametrów. W tym kursie wpisaliśmy wartości jak na poniższym ekranie:

Ekran tworzenia nowego repozytorium
Tutaj zatrzymamy się na chwilę nad opcjami w dolnej części formularza. Są one specyficzne dla platformy GitHub.com i (prawie) nie są związane bezpośrednio z Gitem jako narzędziem, ale warto o nich wiedzieć.
Pierwsza z nich to ‘Initialize this repository with a README’ — w momencie utworzenia repozytorium utworzony zostanie plik readme z przykładowym opisem stworzym z użyciem składni markdown. GitHub automatycznie wyświelta ten plik na stronie przeglądania repozytorium, co jest niezwykle wygodne w przypadku bibliotek i projektów Open Source — pozwala zamieścić tam najważniejsze informacje, odniesienia do dokumentacji, przykłady itp. Dodatkowo GitHub nieco rozszerza składnię markdown o własne elementy.
Druga opcja to plik .gitignore — plik ten jest standardowym elementem Git’a i służy do ignorowania określonych plików (a dokładniej ścieżek) — dzięki temu pliki, które pasują do zapisanych tam wzorców, nie pokazują się w kliencie jako zmiany, nie są także wysyłane na serwer. To bardzo poręczna funkcja, a GitHub dodatkowo ją ułatwia — możemy wybrać predefiniowany plik .gitignore dla narzędzia/języka, którego używamy (np. Maven ignoruje wszystko w katalogach /target, a Eclipse pliki specyficzne dla Eclipse).
Ostatnia z opcji to wybór licencji — pozwala na dołączenie do repozytorium wybranej licencji, dzięki czemu nie musimy się martwić szukaniem jej treści, wklejaniem itp. Bardzo proste i funkcjonalne narzędzie. PS. Jeśli chcesz wybrać licencję do swojego projektu, ale przytłacza Cię ich ilość, drobne różnice itp, polecamy serwis tldrlegal.com — znajdziesz tam zwięzłe podsumowanie każdej popularnej licencji (co można, czego nie można, co jest wymagane), co pozwoli uniknąć Ci bólu głowy nawigując po różnych prawnych tekstach i zawiłościach.
W tym momencie repozytorium zostanie utworzone, a Ty zostaniesz przeniesiona na jego główną stronę — przeglądarkę zawartości.
Korzystamy z GitHub.com
W tym miejscu powiemy sobie parę słów o interfejsie github.com oraz funkcjonalnościach, jakie tam znajdziemy. Główny ekran naszego repozytorium wygląda następująco:
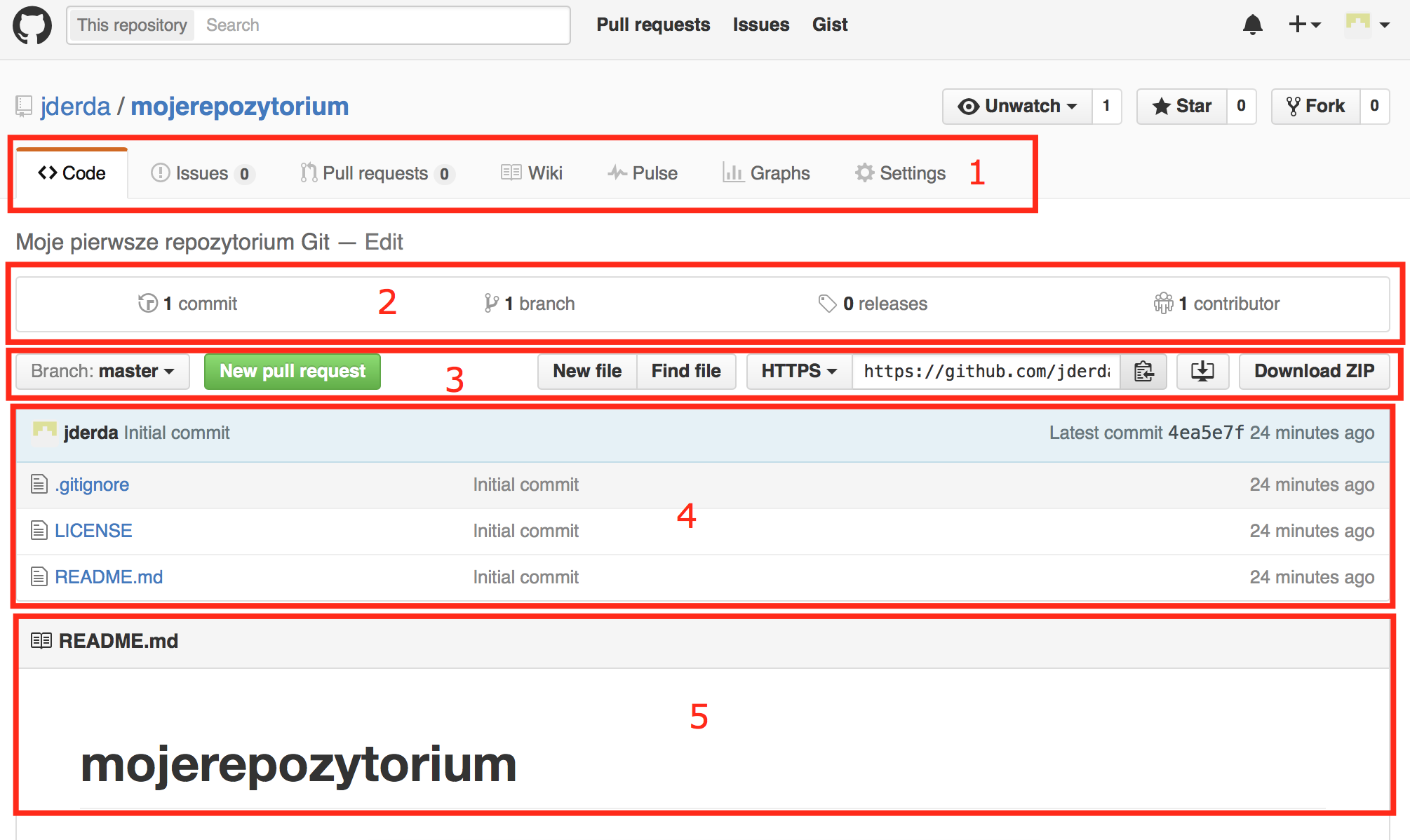
Główna strona repozytorium GitHub
Okno to ma kilka sekcji:
- Narzędzia repozytorium — tutaj znajdziemy opcje repozytorium (gdzie możemy zmienić nazwę, dodać uprawnienia itp) ale także wiki i ‘issues’ — proste moduły do prowadzenia dokumentacji i obsługi zgłoszeń (możemy je wyłączyć z poziomu opcji) oraz odnośniki do podsumowań takich jak pulse (zdarzenia związane z naszym repozytorium), graphs (podobnie do pulse, tylko w postaci graficznej) oraz pull requests (to sposób, w jaki każdy może ‘zaproponować’ dodanie czegoś do repozytorium, nawet jeśli nie posiada do niego uprawnień; jest to także sposób na code review za pomocą GitHub’a)
- Statystyki — krótkie podsumowanie ilości branchy, commitów, wydań oraz osób mających uprawnienia do wysyłania kodu do repozytorium (każda z opcji jest klikalna, co przenosi nas na odpowiednią stronę ze szczegółami)
- Szczegóły repozytorium — tutaj znajdziemy m.in. opcję zmiany brancha, wyszukiwania, jak i pobierania danego brancha w postaci paczki ZIP oraz link do pobrania go na swój komputer (o tym powiemy sobie za moment)
- Pliki i katalogi — dzięki temu możemy nawigować po repozytorium przechodząc wgłąb katalogów czy podglądając pliki; w górnej części jest też skrócona informacja o ostatnim commicie, kiedy nastąpił oraz kto był jego autorem
- Readme — jeśli bieżący katalog zawiera plik README.md, tutaj będzie wyświetlona jego zawartość w postaci ‘uładnionej’
Informacje o commicie
W górnej części okna widzimy ostatni commit w danym katalogu — możemy kliknąć w niego, aby zobaczyć jego szczegóły. Można także kliknąć przycisk ‚commits’, aby przejrzeć pełną historię commitów, klikając na dowolny z nich przechodzimy do jego podsumowania.
Podsumowanie commita zawiera najważniejsze informacje — kto i kiedy go dokonał, wiadomość do niego dołączoną oraz podsumowanie zmian — tzw. diff. Podsumowanie to po lewej stronie pokazuje jak ‚było’, a po prawej wprowadzone zmiany. Całość jest kolorowana aby ułatwić nawigację — kolor czerwony oznacza usunięte elementy, zielony dodane, a żółty zmiany. Na widoku tym możemy też wybrać commit, z którym porównujemy — możemy więc obejrzeć zmiany kilku commitów razem, co znacznie ułatwia ‚ogarnięcie’ co zostało zmienione w serii commitów.
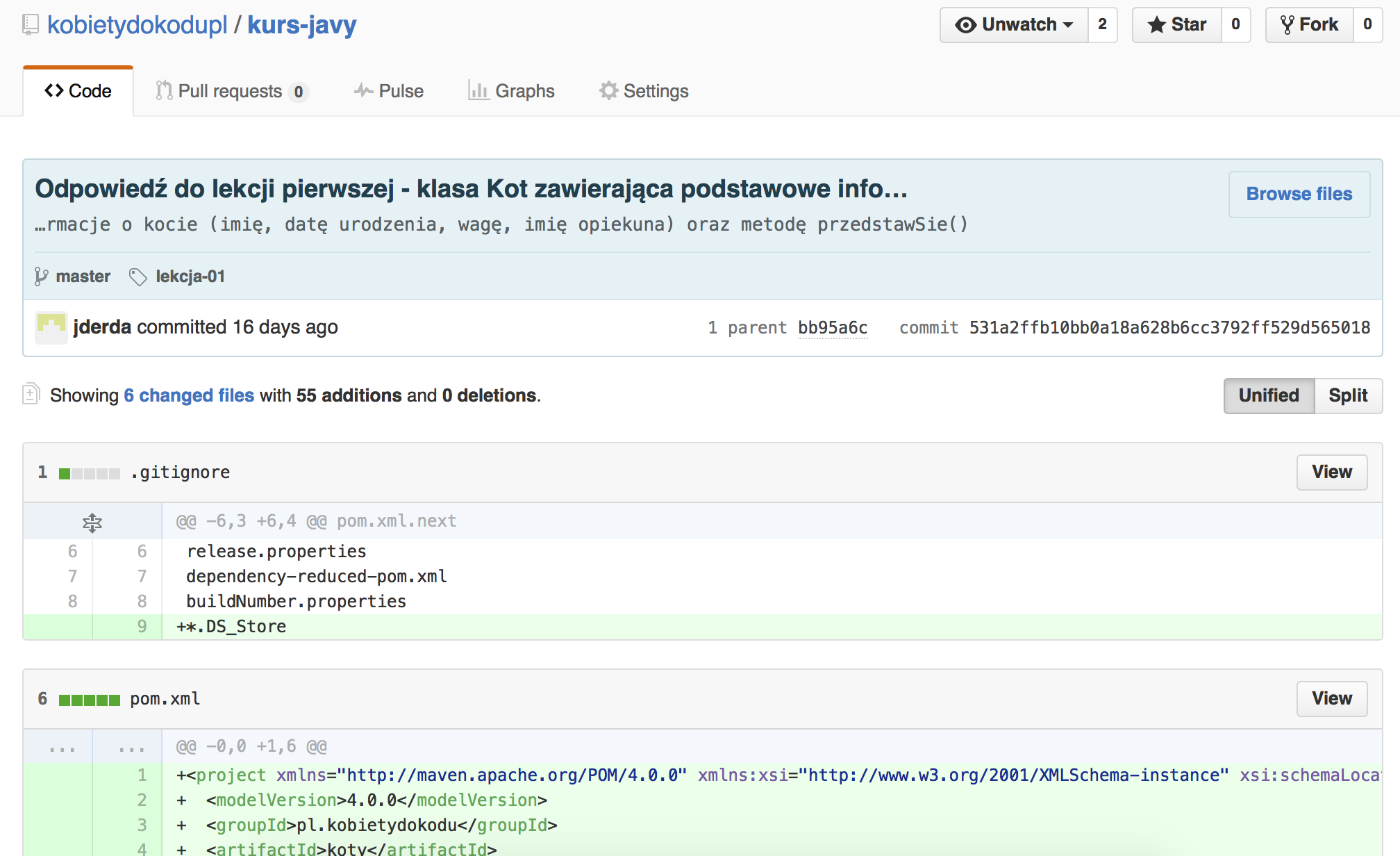
Widok commita w serwisie github.com
‘Blame’ czyli lekcja historii
Kolejną bardzo przydatną funkcją jest tzw. blame — funkcjonalność pozwalająca ‚odszukać’ kto był autorem ostatnich zmian w wybranym pliku / linijce. Jest to funkcjonalność dostępna zarówno poprzez interfejs SmartGit jak i GitHub
Przeglądając pliki w repozytorium możemy przełączyć się na widok ‘blame’. Wtedy po lewej stronie znajdziemy pasek z listą commitów i różnymi odcieniami pokazujący, z którego commita pochodzi konkretna linia. Odcień także ma znaczenie — im jaśniejszy, tym ‚nowsza’ zmiana — dzięki temu możemy się szybko zorientować czy interesujący nas fragment był niedawno modyfikowany, bez czytania szczegółów commitów.

Widok ‘blame’ pliku na github.com
Forkowanie repozytorium
Czasem zdarza się, że chcemy pobrać czyjeś repozytorium, skopiować je w całości, a następnie pracować niezależnie od niego. To bardzo częsta praktyka w przypadku projektów open source, ale także bardzo dużych projektów. Operacja ta nosi nazwę fork — od angielskiego słowa oznaczającego ‚rozgałęzienie’ lub ‚rozgałęziać’.
W serwisie GitHub operacja ta jest banalna, i sprowadza się do jednego kliknięcia — nad repozytorium do którego mamy dostęp, wystarczy kliknąć przycisk ‚fork’. Dzięki temu uzyskamy kopię repozytorium całkowicie pod naszą kontrolą.
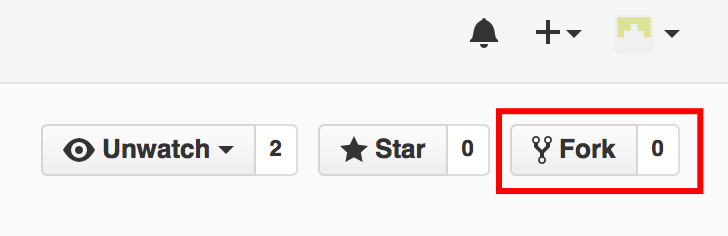
Forkowanie repozytorium w GitHub
Kopia dotyczy całości repozytorium — tzn kopiowana jest także historia zmian i wszystkie branche (o branchach powiemy sobie nieco więcej w dalszej części). Oczywiście możemy je usunąć tak jak usuwalibyśmy we własnym repozytorium.
Co ważne, wszelkie zmiany wprowadzone w naszej kopii repozytorium nie są widoczne w ‚oryginale’, podobnie jak w drugą stronę — od tej pory są to dwa niezależne repozytoria. Możemy jednak świadomie ‚przesyłać’ zmiany pomiędzy nimi, co także jest widoczne jako pull requesty.
Inne funkcje
GitHub oferuje wiele innych dodatkowych narzędzi, o których możnaby napisać naprawdę długi wpis. Omówiliśmy te najważniejsze, a zainteresowanych odsyłamy do pomocy GitHub, która jest naprawdę dobrze napisana.
Korzystamy z repozytorium zdalnego
W tym momencie mamy już repozyturium utworzone na serwerze, GitHub sam umieścił w nim kilka plików, czas pobrać je na nasz komputer oraz dokonać jakichś zmian! Na początku pokażemy drogę ‘domyślną’, w przypadku GitHub’a oraz SmartGit’a jest też droga ‘na skróty’, o której krótko będzie poniżej.
Uruchom SmartGit — powinnaś zobaczyć puste okno z kilkoma zakładkami, które może nieco przerażać. Nie ma się jednak czego bać ;)
Okno SmartGit
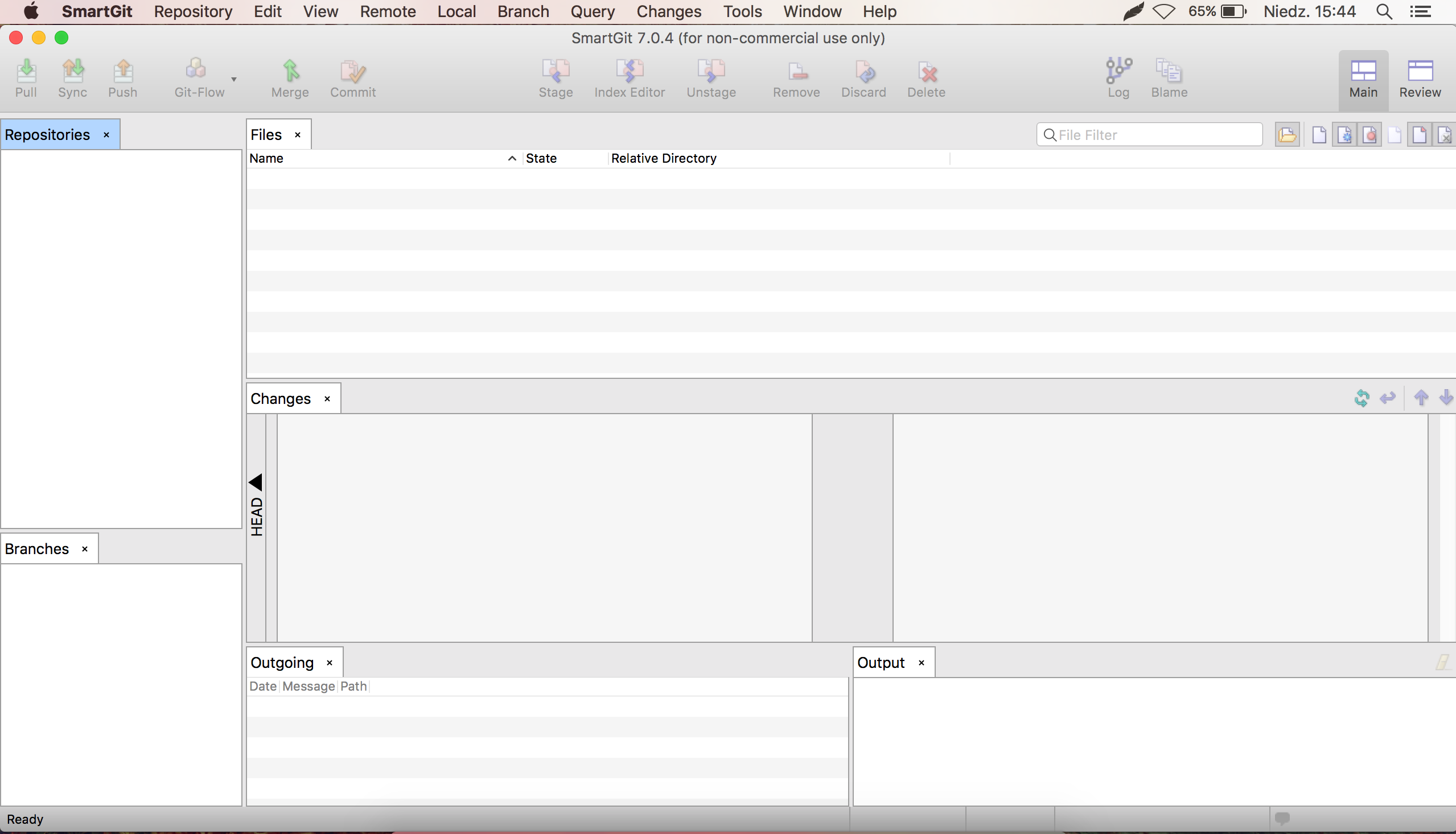
Główne okno programu SmartGit
Główne okno podzielone jest na kilka ‘sekcji’, z których każda ma określone zastosowanie. Okienka te możemy oczywiście otwierać / zamykać / przemieszczać wg uznania, powyższy widok jest widokiem domyślnym.
- menu rozwijane — oferuje dostęp do wszystkich funkcji programu, pozwala także otworzyć sekcje, które nie są w danej chwili widoczne
- menu górne — najczęściej używane funkcje zebrane w postaci dużych przycisków, do których zawsze mamy szybki dostęp
- repositories — lista repozytoriów zarządzanych z poziomu SmartGit’a, pozwala także przełączać się pomiędzy nimi oraz przeglądać drzewo katalogów
- files — lista plików w wybranym katalogu / repozytorium
- changes — po wybraniu pliku, w tej części możemy podejrzeć modyfikacje, jakie zostały dokonane względem wersji ‘z repozytorium’
- branches — lista branchy w repozytorium, z którym obecnie pracujemy, zarówno tych dostępnych lokalnie jak i zdalnych
- outgoing — list commitów, które nie zostały jeszcze przesłane na server (nie została dla nich wykonana operacja push — więcej o tym poniżej)
- output — historia poleceń, które wykonywaliśmy na repozytorium; co ciekawe, pokazane są komendy, jakich moglibyśmy użyć także pracując z GITem w konsoli — przydatne do nauki poleceń GIT’a lub weryfikacji, co się tak naprawdę dzieje
Klonowanie repozytorium
Mamy więc już repozytorium na serwerze, aby skopiować je na własny komputer i rozpocząć pracę, musimy wykonać operację, która w Git nazywa się klonowaniem. W tym celu wybieramy opcję clone z menu głównego.
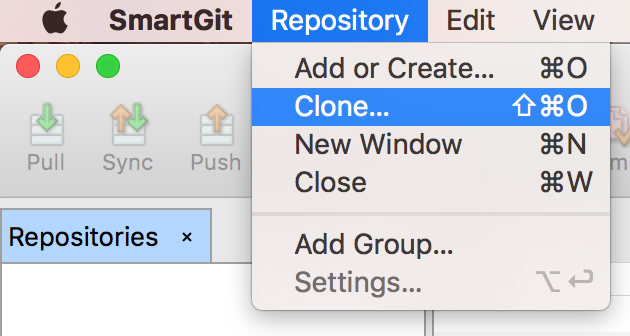
Opcja klonowania repozytorium w górnym menu
w kolejnym kroku musimy podać adres repozytorium — znajdziemy go na GitHub na głównej stronie repozytorium, np. https://github.com/kobietydokodupl/kurs-javy.git . Przechodząc dalej możesz także zostać poproszona o hasło, jeśli nie zostało wcześniej zapamiętane.
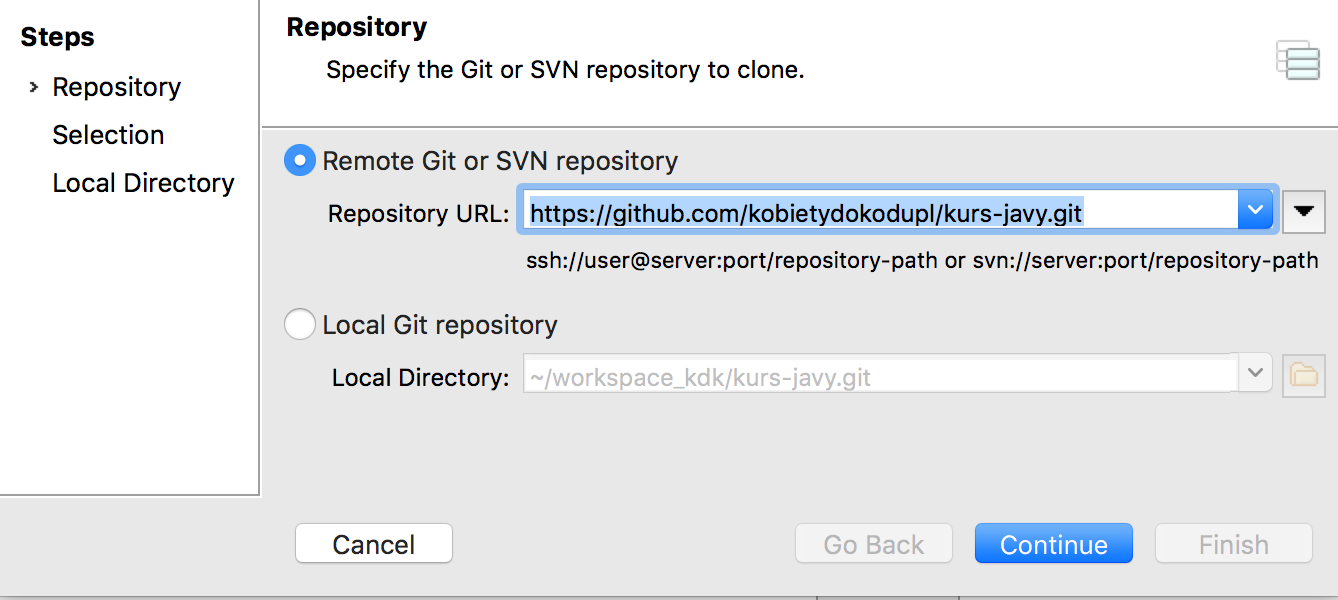
Wybór repozytorium zdalnego
Następnie wybieramy lokalizację na dysku, gdzie chcemy pobrać repozytorium. Jeśli wybrany folder jest pusty, to pliki zostaną pobrane bezpośrednio do niego. Jeśli nie, zostanie w nim utworzony nowy folder o nazwie takiej jak repozytorium.
Po chwili repozytorium zostało już skopiowane na nasz komputer — możemy pracować z nim lokalnie, dokonywać commitów czy też przeglądać historię zmian lokalnie.
Opcja alternatywna: podpięcie konta
SmartGit umożliwia podpięcie konta z jednego z dostępnych systemów kontroli wersji, w tym GitHub, i korzystanie z niego w kilku miejscach. Jest to ułatwienie pozwalające nam nie wprowadzać hasła wielokrotnie oraz wybierać repozytorium z listy dostępnych zamiast kopiować jego ścieżkę.
Pierwszym krokiem jest konfiguracja konta — w tym celu otwieramy preferencje a następnie wybieramy z menu opcję hosting providers.
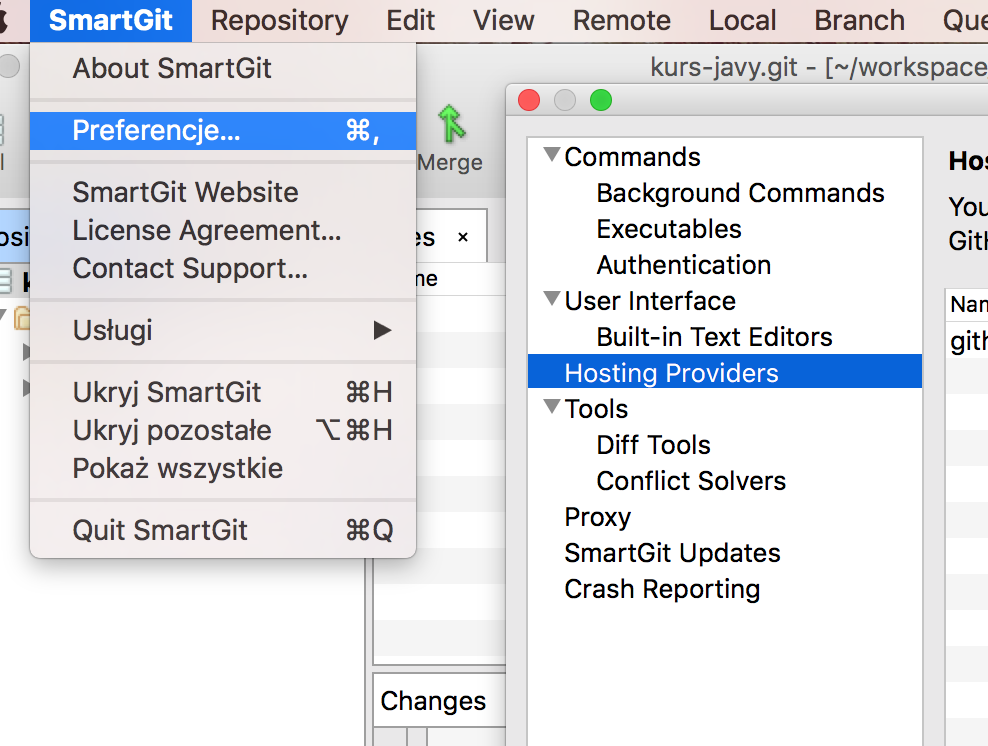
Ustawienia ‘hosting providers’ w SmartGit
W tym miejscu musimy podać token — najprostsza opcja to wygenerowanie tokenu za pomocą przycisku — w tym celu zostaniemy poproszeni o podanie loginu i hasła. Wygenerowany zostanie token, który pozwala SmartGitowi korzystać z GitHub’a nie używając bezpośrednio Twojego hasła, co jest bezpieczniejszą opcją. Dostęp ten możesz w każdym momencie wycofać korzystając z github.com (zakładka Applications w ustawieniach konta)

Dodawanie konta GitHub
Po dodaniu konta wybierając repozytorium, z którego chcemy korzystać, mamy możliwość wybrania wszystkich, do których ma dostep nasze konto bezpośrednio z poziomu okna wyboru:
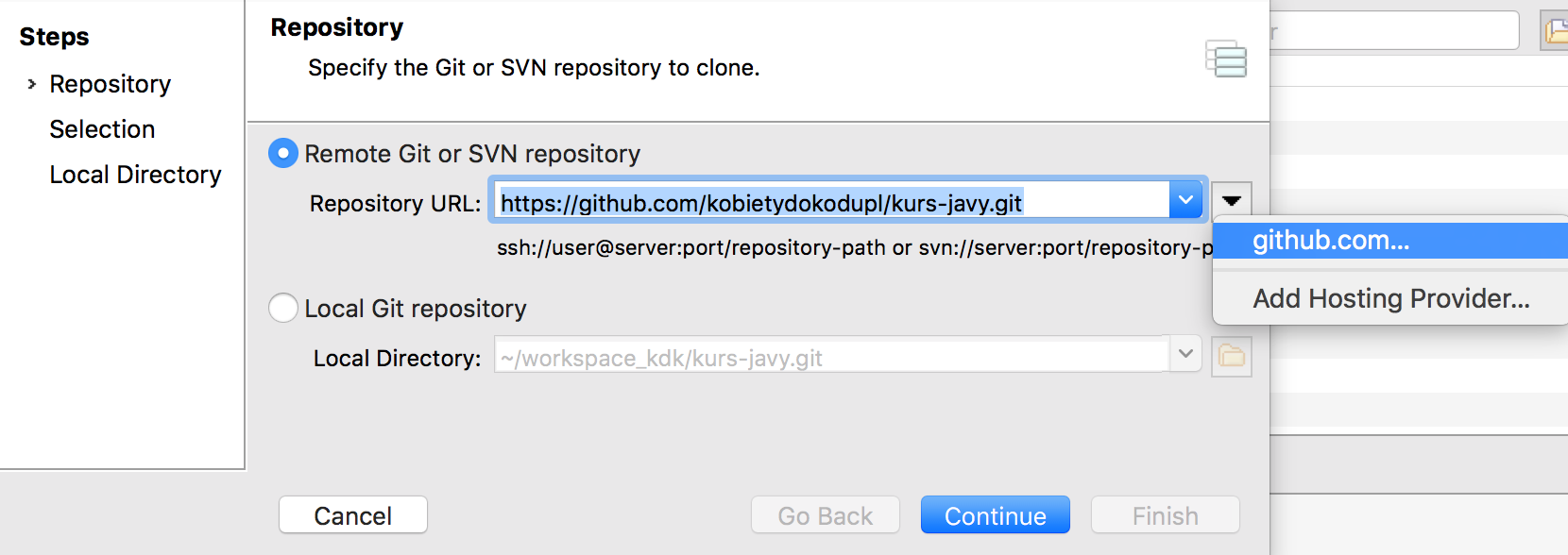
Wybór repozytorium zdalnego — GitHub
Modyfikacje, dodawanie i usuwanie plików
Masz już kopię repozytorium lokalnie, na swoim dysku. Praca z tymi plikami wygląda identycznie jak z normalnymi plikami na dysku — możesz tworzyć pliki, usuwać je, modyfikować, zmieniać im nazwy itp. Zmiany te nie pojawią się jednak ‚automatycznie’ w repozytorium.
Przede wszystkim musimy powiedzieć Gitowi które zmiany chcemy zachować, a które odrzucić. Najczęściej chcemy zachować wszystkie zmiany, ale może się także zdarzyć sytuacja, w której dokonaliśmy jakichś zmian i chcemy je przywrócić do wersji wcześniejszej. Pomoże nam w tym klient Git — w tym wypadku SmartGit. W głównym oknie programu domyślnie widzimy tylko pliki, które różnią się od tych zapisanych w pamięci Git’a. Klikając w wybraną pozycję możemy podejrzeć jakie są różnice pomiędzy stanem zapisanym (czyli ostatnim commitem) a bieżącym.
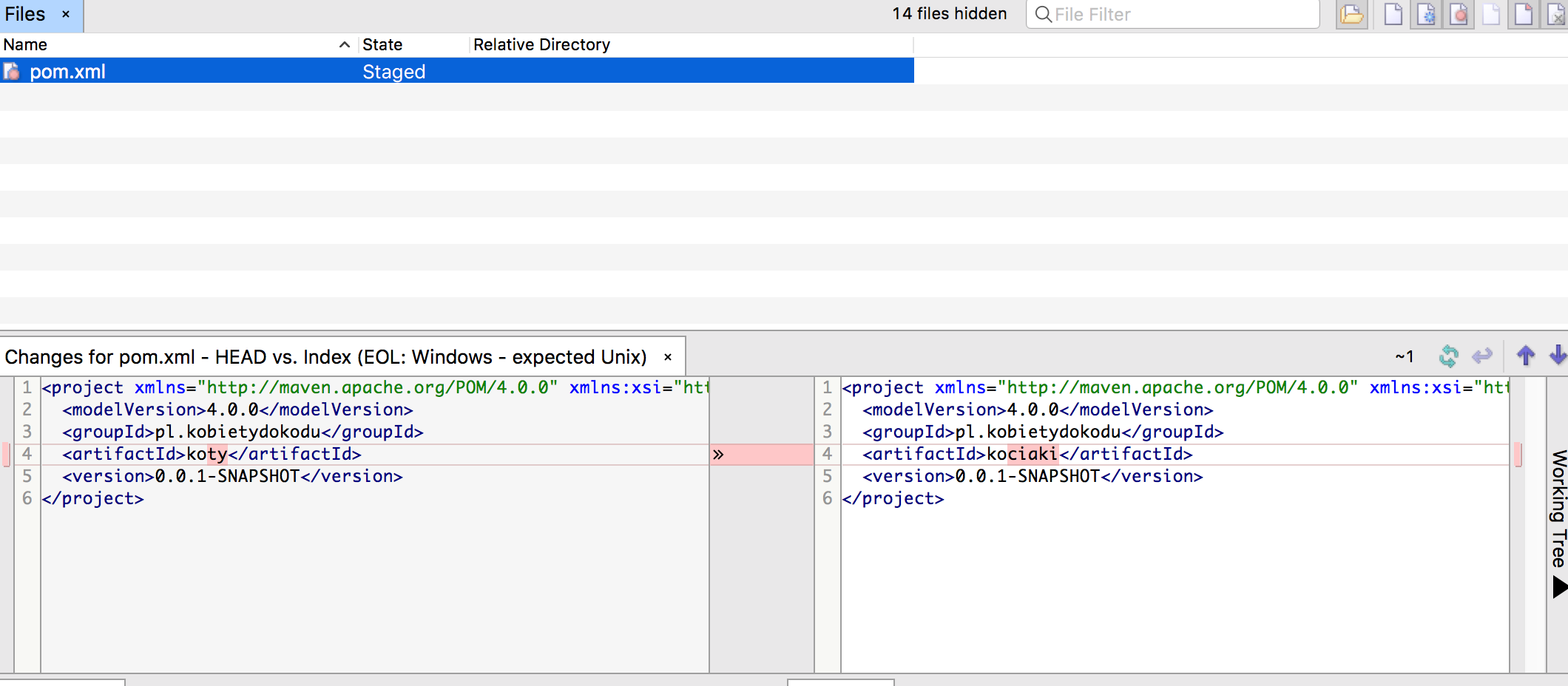
Przykładowa ‘różnica’ pomiędzy plikami
SmartGit pozwala ‚dodać’ wybrane zmiany przed ich zapisaniem (wykonaniem operacji commit) — służy do tego przycisk ‚Stage’ w górnej belce. Analogicznie przycisk ‚Discard’ pozwala odrzucić zmiany i przywrócić ostatnio zapisaną wersję (uwaga: ta operacja jest nieodwracalna!).

Przyciski ‘stage’ i ‘discard’ w głównym oknie SmartGit
Mając wybrane zmiany, które chcemy commitować, klikamy na przycisk Commit — tutaj SmartGit pozwala nam nie tylko uzupełnić wiadomość, jaka będzie powiązana z commitem, ale także ponownie przejrzeć, które zmiany wybraliśmy, a których nie, i zmienić naszą decyzję w razie potrzeby. Jeśli ostatnie zmiany są zapisane tylko lokalne (tzn. nie wysłaliśmy ich jeszcze na centralne repozytorium), mamy opcję pozwalającą zmodyfikować ostatni commit zamiast tworzyć nowy.
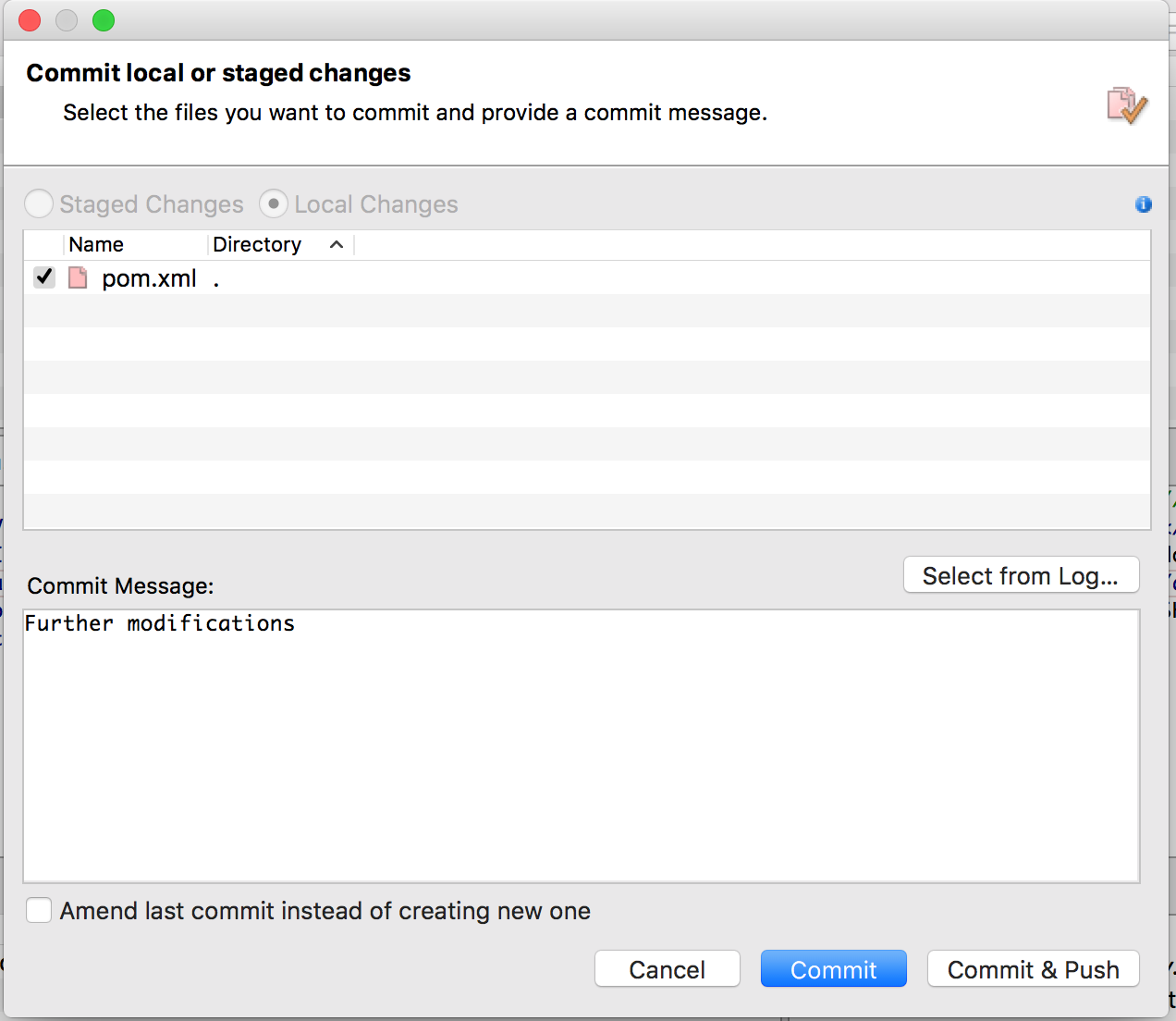
Okno commitowania plików
W tym momencie nasze zmiany są już gotowe do wysłania na serwer — możemy użyć opcji Sync, która jest połączeniem opcji Pull oraz Push (w tej kolejności). Operacja Pull pozwala nam na pobranie ostatnich zmian z repozytorium centralnego, operacja push wysyła wszystkie commity, które są tylko lokalnie, na repozytorium centralne.
Commit obejmuje dowolne zmiany w plikach — nie tylko modyfikacje czy dodawanie, ale także zmianę nazwy czy ich usuwanie.
Uwaga: Git nie przechowuje katalogów, a jedynie pliki! Oznacza to, że jeżeli katalog jest pusty, to nie będzie on widoczny w repozytorium — katalogi w Git są ‚skutkiem ubocznym’ plików w nich umieszczonych (Git mówiąc w uproszczeniu przechowuje ścieżki plików wewnątrz repozytorium, na tej podstawie może określić jakie katalogi są ‚widoczne’).
Uwaga 2: O ile Git jest w stanie przechowywać pliki binarne (np. grafiki, filmy, zdjęcia, dokumenty word itp), jego algorytmy i protokół są zoptymalizowane do pracy z plikami tekstowymi — takimi jak np. kody źródłowe. Większość narzędzi jak np. różnice, historia zmian, blame czy rozwiązywanie konfliktów traci sens w przypadku plików binarnych z uwagi na sposób, w jaki są one tworzone (np. zmiana kilku liter w dokumencie word może całkowicie zmienić cały plik docx, w którym ta zmiana się znajduje). Choć ich przechowywanie w repozytorium Git jest możliwe, Git nie nadaje się do przechowywania dużej ilości plików, które nie są tekstem.
Praca z branchami
Bardzo ważną funkcją systemów kontroli wersji są branche — czyli ‚odgałęzienia’ głównej linii kodu, na których można pracować niejako w ‚izolacji’. Jest to bardzo ważne nie tylko w ogromnych projektach, gdzie wiele osób pracuje jednocześnie nad wieloma rzeczami, ale także w mniejszych zespołach. Branche pozwalają także na eksperymentowanie i wprowadzanie zmian bez wpływu na główny branch (najczęściej zwany master), wprowadzanie większych modyfikacji w sposób przyrostowy a także zarządzanie np. dwiema różnymi wersjami produktu.
Tworzenie nowych branchy
Aby dodać nowy branch wystarczy w oknie SmartGit w menu Branch wybrać Creat new, a następnie podać jego nazwę. Stworzy to nowy branch i przełączy Cię od razu na niego. Branch ten będzie widoczny na serwerze centralnym po następnej operacji push.
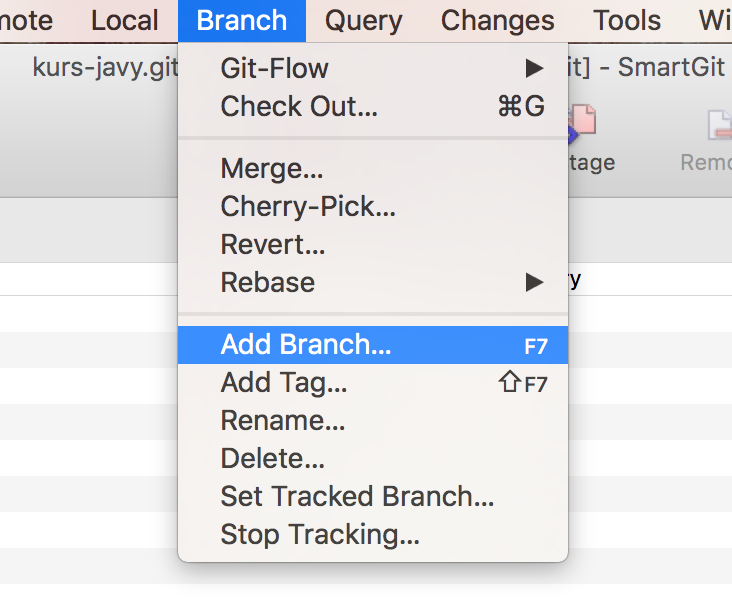
Dodawanie nowego brancha
Pobieranie istniejących branchy i ich używanie
Domyślnie w lewym dolnym rogu mamy listę branchy, o których SmartGit ‚wie’ — zarówno tych lokalnych, jak i tych istniejących tylko zdalnie.
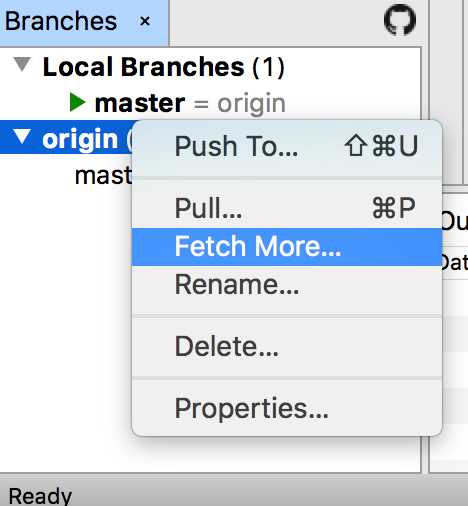
Lista branchy
Aby odświeżyć listę zdalnych branchy możemy kliknąć prawym przyciskiem myszy na repozytorium, po czym wybrać opcję ‚Fetch’ — dzięki temu pobrane zostaną nowe branche, o ile istnieją. Przełączenie się na lokalny lub zdalny branch sprowadza się do dwukrotnego kliknięcia na niego. W przypadku branchy zdalnych, zostanie on najpierw pobrany lokalnie, a dopiero później nastąpi przełączenie.
Aktualnie wybrany branch, na którym pracujemy, wyróżniony jest pogrubieniem.
Operacja stash / unstash
Pracując z branchami mamy dostepne także operację zwaną stash — jest to coś w rodzaju ‚schowka’, na którym możemy umieszczać zmiany, które chcemy zachować, ale niekoniecznie commitować. Stash jest tylko lokalny, nie ma możliwości jego synchronizacji z serwerem zdalnym i jest niezależny od brancha. Jest on przydatny np w sytuacji kiedy wprowadzamy jakieś zmiany, po czym musimy przełączyć się na inne zadanie lub chcemy określone zmiany jednak umieścić na innym branchu. Stash jest też wykorzystywany przy pullowaniu zmian — każda operacja pull to tak naprawdę umieszczenie zmian na stosie, pobranie najnowszej wersji, a następnie próba przywrócenia tych zmian ze stosu.
Aby dodać zmiany na stos, wystarczy wybrać opcję Local -> Save stash changes z menu
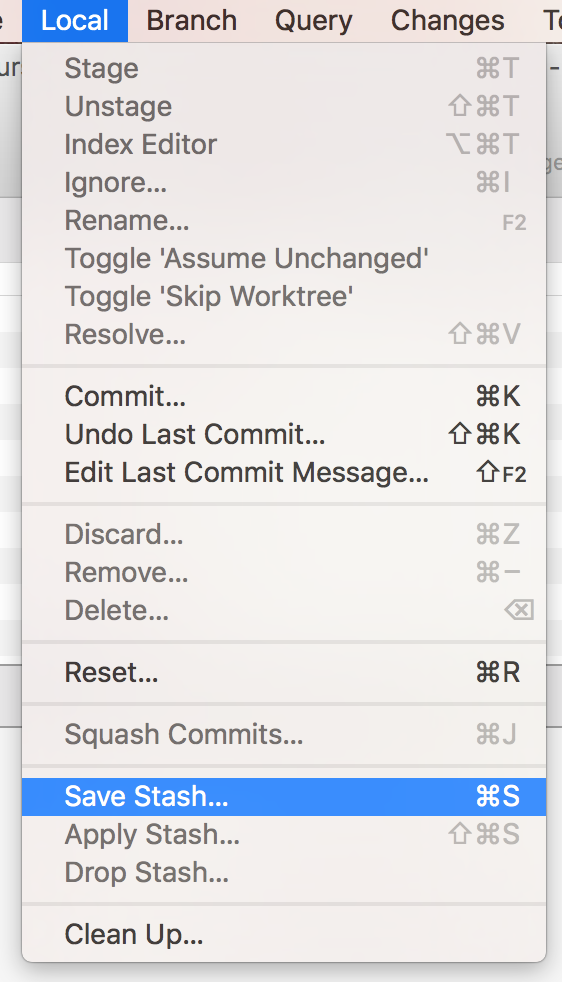
Zapisz zmiany na stos
Podobnie z ‚przywracaniem’ zmian — wybieramy zmiany, które nas interesują, po czym są one ‚nakładane’ na bieżącą wersję plików. Służy do tego opcja w menu Local -> Apply stash
Rozwiązywanie konfliktów
Wspomniana wcześniej operacja pull może prowadzić do konfliktów — jeśli wprowadziłaś modyfikacje w pliku, który zmienił się na repozytorium centralnym od ostatniego razu, jak robiłaś pull, może to spowodować, że Git nie będzie w stanie samodzielnie połączyć tych zmian. Spowoduje to tzw. konflikt — sytuację, która wymaga manualnego rozwiązania. W SmartGit objawia się to plikiem z czerwoną ikonką.
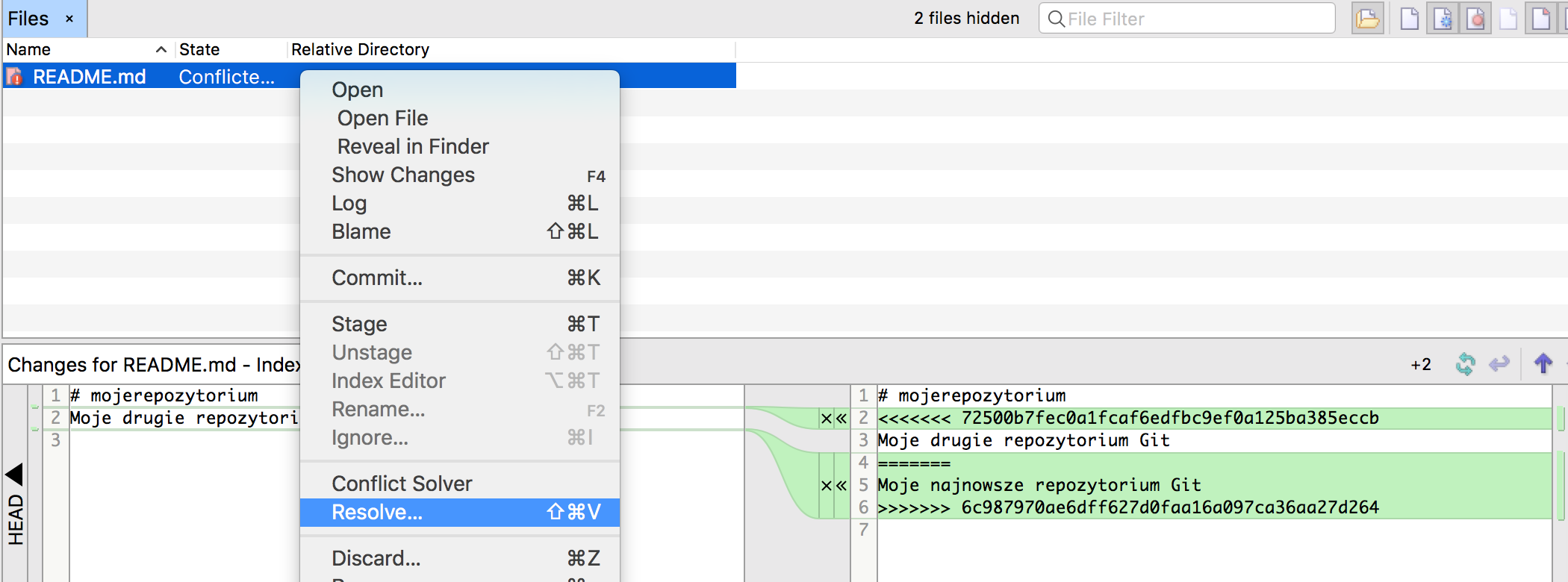
Plik w statusi ‘konflikt’ (na dole widoczne ‘adnotacje’ Git’a w problematycznym miejscu)
Git automatycznie tworzy dwa pliki tymczasowe — zawierające sporny plik w wersji z repozytorium i w wersji lokalnej — oraz w rzeczonym pliku w spornych fragmentach dodaje stosowne adnotacje. Konflikty można rozwiązywać ręcznie — odpowiednio modyfikując dany plik w wybranym przez nas edytorze — lub korzystając z opcji ‚Resolve conflicts’ w SmartGit. Opcja ta pozwala w sposób graficzny, po kolei dla każdej ze zmian, które są w konflikcie, wybrać właściwą zmianę lub samodzielnie zmodyfikować kod tak, aby był prawidłowy. Po rozwiązaniu konfliktów ‚informujemy’ o tym Git’a poprzez wykonanie operacji commit.
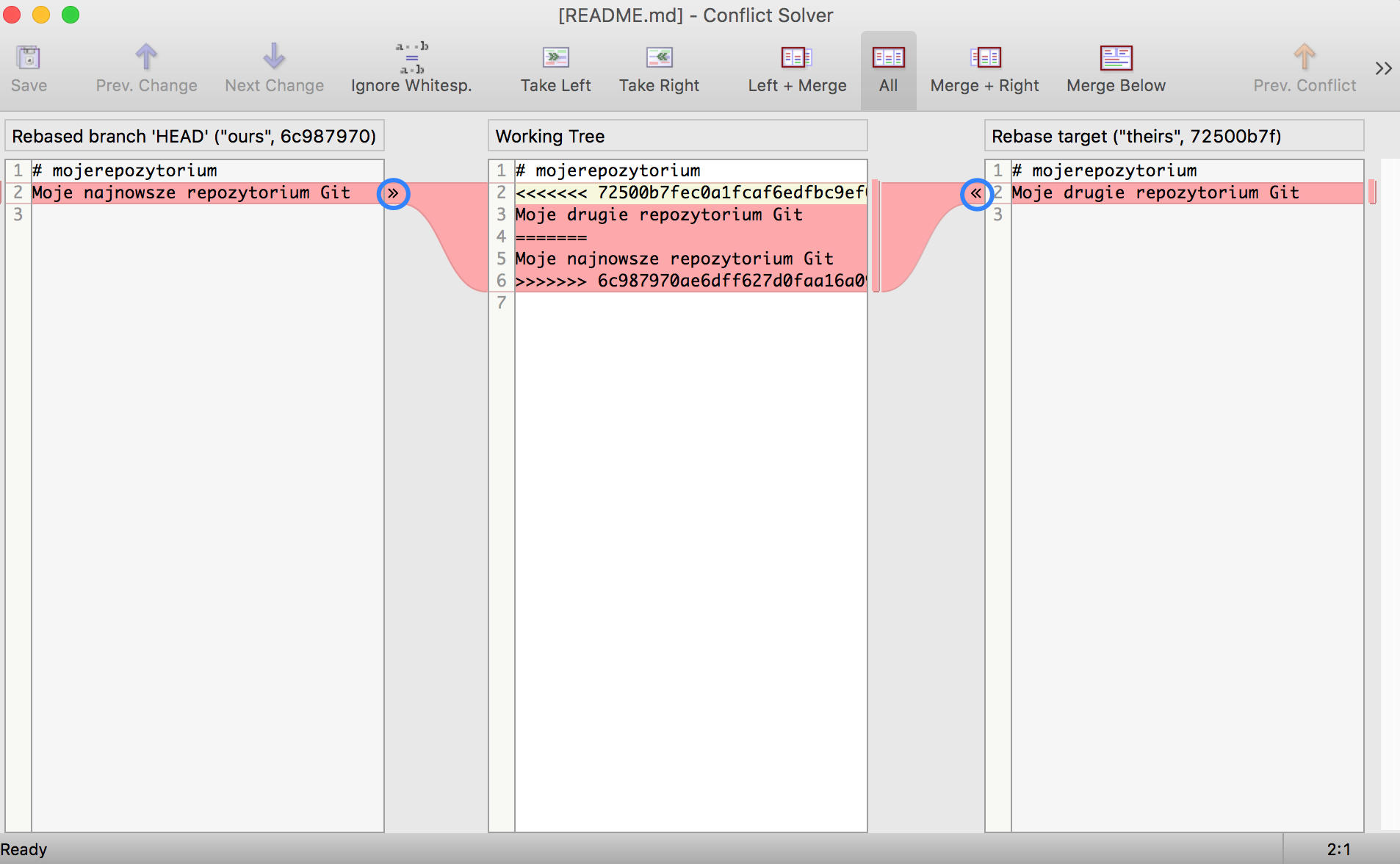
Rozwiązywanie konfliktu — na niebiesko zaznaczone są strzałki, które pozwalają szybko wybrać ‘wersję’, którą chcemy zachować (możliwa jest też edycja ręczna, w środkowym oknie)
Wiadomości commitów
O ile dla Ciebie ‚fix błędu’ może mieć sens i możesz wiedzieć o co chodzi, za miesiąc nie będziesz już pamiętała — co to był za błąd, dlaczego trzeba było go poprawić, jak dokładnie został poprawiony itp. Dobrą praktyką jest dołączanie numeru ticketa do wiadomości commita, o ile taki posiadamy — dzięki temu można w przyszłości prześledzić cała historię błędu w razie potrzeby i uzasadnienie wprowadzenia określonej zmiany. Przykład wiadomości commita, która pozwoli w przyszłości zrozumieć cel danej zmiany:
[PROJEKT-123] Zmiana kodowania zapytań HTTP z UTF‑8 na UTF-16 w celu zgodności z systemem XYZ
Nie bój się też ‚upominać’ innych osób w zespole — na dobrych opisach commitów zyska ostatecznie cały zespół.
Branch na każdą funkcjonalność
W przeciwieństwie do innych systemów kontroli wersji jak np. SVN, stworzenie brancha jest ‚tanie’ — nie ma potrzeby kopiowania całej zawartości repozytorium, nie wymaga to wiele dodatkowego miejsca na dysku czy innych zasobów. Dlatego dobrą praktyką jest tworzenie nowego brancha dla każdej funkcjonalności / zadania, nad którym pracujemy. Nie tylko ułatwi to innym przejęcie pracy po nas w razie potrzeby, ale dodatkowo izoluje nas od innych zmian podczas pracy nad konkretnym celem. Oczywiście po połączeniu zmian z główną gałęzią, branche takie można usunąć lub pozostawić wg preferencji zespołu.
Pewnym uproszczeniem (choć stworzenie brancha zajmuje naprawdę chwilę) jest tworzenie brancha dla każdego developera — przeważnie jedna osoba pracuje nad jedną funkcjonalnością w danym momencie, więc jest to podobne rozwiązanie (choć nieco mniej przejrzyste)
Pushowanie wyłącznie gotowych funkcjonalności
Pracując nad większą funkcjonalnością najprawdopodobniej dokonasz commit kilkukrotnie w trakcie — zarówno po to, aby zorganizować sobie pracę, ale także być może chcesz wprowadzić jakąś zmianę, którą możesz chcieć wycofać. Pamiętaj jednak, żeby nie pushować zmian, które nie są ostateczne — repozytorium zdalne jest wspólnym miejscem pracy całego zespołu, i przez niekompletne zmiany możesz np. zepsuć build lub spowodować, że ktoś pobierze niedziałającą wersję do dalszej pracy. Pamiętaj jednak, że nie warto przesadzać — jeśli kodowanie nowej funkcjonalności zajmie Ci tydzień, powinnaś rozbić ją na mniejsze ‘podfuncjonalności’ i w takiej postaci pracować nad nimi czy je pushować. Przed wypushowaniem swojego commita musisz zawsze zadać sobie pytanie, czy “nie popsuje on aplikacji” i jeśli nie, to możesz to zrobić.
Oczywiście każda osoba powinna pracować na osobnym branchu, ale są różne sytuacje i warto pracować z założeniem, że zmiany widoczne dla wszystkich na branchu są kompletne lub co najmniej nie psują innych funkcjonalności.
Łączenie wielu commitów przed pushem
Dobrym nawykiem jest commitowanie lokalnie jak najczęściej — dzięki czemu mamy pełną historię zmian, którą możemy przeglądać lub wracać do niej i ‚’cofać się’ do dowolnego punktu w czasie. Wyglądało by to jednak nieestetycznie na repozytorium centralnym, utrudniało wyszukiwanie informacji, która nas interesuje i śledzenie historii zmiany. Warto przed wykonaniem operacji push połączyć wszystkie commity związane z jedną funkcjonalnością / zadaniem w jeden. Służy do tego operacja Squash commits w menu Local.

Menu z opcją squash commits
Aby operacja ta była dostępna, musisz wybrać commity do połączenia w oknie ‚outgoing’. Uwaga: nie da się łączyć commitów, które zostały już wypushowane! Opcja ta dostępna jest także po kliknięciu prawym przyciskiem myszki na zaznaczonych commitach.

Okienko ‘outgoing’ i opcja squash commits
Okno pozwala nam wybrać opis zmian, który będzie widoczny w logu oraz autor, który zostanie do nich przypisany (musi to być jeden z autorów łączonych commitów)
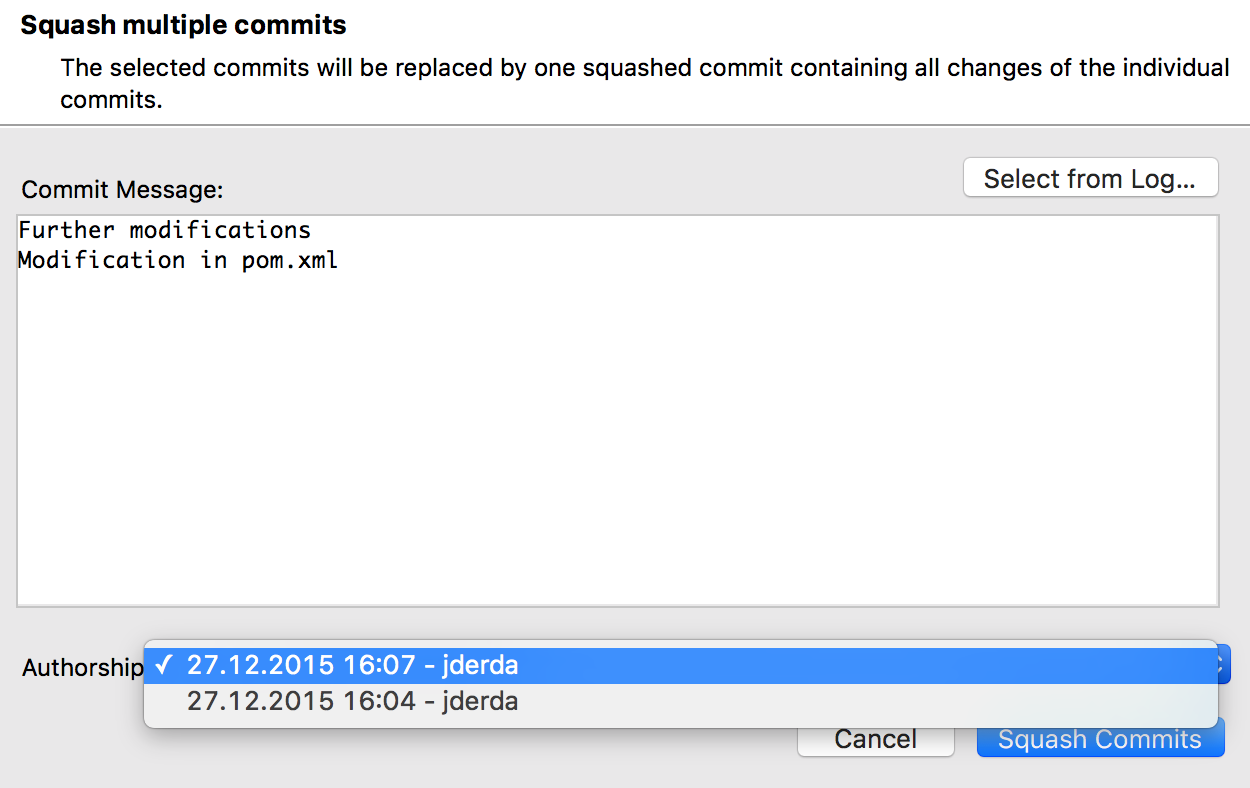
Okno łączenia commitów
Podsumowanie
Wytłumaczyliśmy sobie podstawowe koncepcje związane z kontrolą wersji oraz jak je stosować w praktyce. Mam nadzieję, że przekonaliśmy Cię że jest to narzędzie zarówno proste, jak i efektywne. Mnóstwo usług czy narzędzi bazuje na git i oferuje także bezpłatny hosting oraz licencje, dzięki czemu można go stosować także do swoich prywatnych projektów bez ponoszenia kosztów. O ile Git ma znacznie więcej możliwości i funkcji, te podstawowe wystarczą Ci do usprawnienia codziennej pracy i zabezpieczenia swoich danych :)
Także od tej pory wszystkie rozwiązania do lekcji, materiały oraz mini-kursy będziemy umieszczać w naszych repozytoriach na GitHub. Dzięki temu każdy będzie mógł w prosty sposób mieć do nich dostęp, przeglądać czy kopiować i modyfikować we własnym zakresie. Link poniżej!
Dodatkowe materiały
- Repozytoria kobietydokodu.pl na GitHub
- Książka Pro Git (dostępna online za darmo z możliwością pobierania)
- Manual do SmartGit
- Tutorial do nauki obsługi gita z linii komend: try.github.io
