
Mamy już podstawowe elementy aplikacji — połączenie z bazą danych, konfiguracje testową, podstawowy model uwierzytelniania i autoryzacji, kolejnym logicznym krokiem jest więc implementacja funkcjonalności. Zanim do tego przejdziemy, warto przygotować projekt pod intensywną pracę — ustawić reguły checkstyle, środowisko CI itp — i tym zajmiemy się dzisiaj.
Każdy projekt oprogramowania można rozbić na dwa elementy — funkcjonalność, czyli wartość jaką projekt dostarcza swoim użytkownikom, oraz potencjał rozwoju (znacznie lepiej pasuje tutaj angielskie słówko — maintanability), który określa jak łatwo jest nasz produkt utrzymywać oraz rozwijać. Oczywiście funkcjonalność, wartość dla użytkowników jest najważniejsza — z tym nikt nie dyskutuje. Jednak fakt, który dość łatwo przeoczyć, to wpływ jakości kodu na zdolność dostarczania funkcjonalności w przyszłości — projekt poprawnie zbudowany od początku wymaga zdecydowanie mniej czasu na wszystkie czynności ‘dookoła’ takie jak utrzymanie, aktualizacje, poprawki błędów, wdrażanie nowej wersji itp. Dzięki temu programiści mają więcej czasu, aby skupić się na potrzebach użytkownika i faktycznie rozwijać aplikację, a nie tylko gasić pożary. To będzie tematem tej lekcji — przygotowanie aplikacji do dalszej efektywnej pracy.
Podstawowe testy aplikacji
Testowanie na tym etapie projektu może wydawać się przesadą — w końcu nasz projekt właściwie nic nie robi. Niemniej jest kilka testów, które mają sens — np. taki, który sprawdza, czy aplikacja się uruchamia. Nie tylko czasem możemy coś przeoczyć (literówka, brak adnotacji, niespełniona zależność itp), ale też testy istniejące od samego początku życia aplikacji wyznaczają pewien standard i konwencje.
Zacznijmy od wspomnianego testu, czy aplikacja się uruchamia. Z pewnością nie jest to test jednostkowy — w końcu nie testujemy pojedynczego komponentu, a całą aplikację. Do tego służą testy integracyjne — ich celem jest sprawdzenie, jak aplikacja wygląda ‘z zewnątrz’ (z punktu widzenia kogoś, kto się z nią integruje — stąd nazwa).
Maven do uruchamiania testów wykorzystuje pluginy o nazwie Surefire oraz Failsafe, w opisie konfiguracji znajdziemy domyślną konwencję jeśli chodzi o testy jednostkowe oraz integracyjne. Niekoniecznie jest to najbardziej czytelna dokumentacja świata, ale dla nas istotne są dwie rzeczy:
- Aby test uruchomił się jako test jednostkowy, nazwa musi spełniać jeden z kryteriów:
- Zaczynać się od Test (np. TestMyFunctionality)
- Kończyć się na Test lub Tests (np. MyClassTest, MyModuleTests)
- Kończyć się na TestCase (np. UserActionTestCase)
- Aby test uruchomił się jako test integracyjny, nazwa musi spełniać jeden z kryteriów:
- Zaczynać się od IT (np. ITMyFunctionality)
- Kończyć się na IT (np. MyApplicationIT)
- Kończyć się na ITCase (np. UserActionITCase)
Oczywiście powyższe odnosi się jedynie do domyślnych ustawień, i możemy je zmienić w zależności od wymagań projektu. Co ważne, wielkość liter ma znaczenie, a jeżeli nasza klasa z testami nie spełnia tych kryteriów, nie będzie ona uruchamiana przez Maven w trakcie budowania projektu! Może to doprowadzić do sytuacji, w której test będzie zwracał błędy, ale nie będzie częścią automatycznego procesu budowania więc będą one przeoczone!
Mając na uwadze powyższe, stwórzmy nasz pierwszy test integracyjny, który sprawdzi, czy aplikacja się uruchamia. Spring Boot posiada bardzo dobre wsparcie do testowania opisane w dokumentacji (uwaga na nazewnictwo klas!). Najprostszy test polega na zainicjowaniu kontekstu oraz założeniu, że jakikolwiek problem spowoduje wyjątek i w efekcie błąd w teście:
@ActiveProfiles("test")
@RunWith(SpringRunner.class)
@SpringBootTest
public class WebappApplicationIT {
@Test
public void contextLoads() {
}
}Jeśli do wygenerowania projektu użyliśmy Spring Initializr, to podobny test będzie już zaimplementowany (aby uruchamiał się jako integration test, wystarczy zmienić jego nazwę wg powyższych wytycznych; dodaliśmy też aktywny profil test). Opiera się on jednak o założenie, że aplikacja rzuci wyjątek w przypadku problemu — w praktyce jest wiele sytuacji, w której wyjątki mogą nie zostać rzucone lub zostaną przechwycone w międzyczasie. Dlatego warto rozszerzyć nasz test tak, aby sprawdzał czy aplikacja faktycznie się uruchomiła.
Aby testy uruchamiały się automatycznie jako część procesu budowania, wystarczy dodać stosowną konfigurację do pliku pom.xml:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-failsafe-plugin</artifactId>
</plugin>To najprostszy sposób na ‘bazowy’ test integracyjny — pozwala nam sprawdzić, czy środowisko jest w stanie się uruchomić i w przypadku problemów zapobiec wdrożeniu takiej wersji na środowiska produkcyjne. Oczywiście to nie powinien być jedyny test integracyjny w aplikacji — innymi zajmiemy się jednak wraz z implementacją funkcjonalności.
Spring Boot Actuator
Powyższą metodę można trochę ulepszyć — moglibyśmy np. sprawdzać określony endpoint naszej aplikacji. Wtedy jednak nasz test staje się wrażliwy na wszelkie zmiany w danym endpoincie, nie jest to więc sytuacja idealna (biorąc pod uwagę, że w tym teście chcemy przetestować całą aplikację, a nie tylko wybrany endpoint). Na szczęście Spring przychodzi z pomocą oferując wbudowane endpointy, które możemy wykorzystać. W naszym teście na ten moment wykorzystamy jedynie endpoint ‘/health’, w praktyce oferują nam one dużo większe możliwości (np. weryfikacje zaaplikowanych migracji bazy danych). Są one częścią Spring Boot Actuator — pakietu narzędzi przydatnych do automatyzacji i zarządzania aplikacją działającą na produkcji. Po bardziej szczegółowy opis odsyłamy do dokumentacji.
W naszej aplikacji wyłączymy więc wszystkie domyślne endpointy, a pozostawimy jedynie /health. Przyda nam się on nie tylko do testów, ale też do zewnętrznej weryfikacji, czy aplikacja działa. Przede wszystkim musimy dodać zależność do naszego pliku pom.xml:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>Następnie do naszego pliku application-properties dodajemy linijki (wyłączamy wszystkie endpointy oraz aktywujemy tylko endpoint /health):
endpoints.enabled=false
endpoints.health.enabled=truePamiętaj także aby zaktualizować ustawienia Spring Security tak, aby każdy bez autoryzacji miał dostęp do ścieżki /health, w tym celu modyfikujemy naszą metodę configure() dodając jedną linijkę:
@Override
protected void configure(HttpSecurity http) throws Exception {
http
.authorizeRequests()
.antMatchers("/health").permitAll()
.anyRequest().denyAll()
.and()
.formLogin()
.disable();
}Modyfikujemy test
Dzięki powyższym zabiegom możemy użyć tego endpointu w naszym teście integracyjnym. Jednocześnie zmodyfikujemy nieco sam test, aby wykorzystywał losowy port, dostępny w systemie (dzięki temu unikniemy potencjalnych problemów podczas jednoczesnego testowania i uruchamiania aplikacji). W tym celu skorzystamy z gotowego przykładu z dokumentacji, nasz test ostatecznie wygląda następująco:
@ActiveProfiles("test")
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = WebEnvironment.RANDOM_PORT)
public class WebappApplicationIT {
@Autowired
private TestRestTemplate restTemplate;
@Test
public void contextLoads() {
ResponseEntity<ObjectNode> response = this.restTemplate.getForEntity("/health", ObjectNode.class);
assertThat(response.getStatusCode()).isEqualTo(HttpStatus.OK);
ObjectNode body = response.getBody();
assertThat(body).isNotNull().isNotEmpty();
JsonNode healthStatus = body.get("status");
assertThat(healthStatus).isInstanceOf(TextNode.class);
assertThat(healthStatus.asText()).isEqualTo("UP");
}
}Zwróć uwagę, że do naszego testu wstrzykujemy TestRestRemplate — ta klasa to nic innego jak wariant RestTemplate, któremu nie musimy podawać adresu naszej aplikacji (np. localhost:8080). Używamy też klasy JsonNode — to jedna z klas biblioteki Jackson, która reprezentuje dowolną strukturę w dokumencie JSON (dziedziczą po niej klasy ObjectNode, ArrayNode, TextNode itp).
Czytelność ponad wszystko
Czytelność kodu jest jednym z ważniejszych elementów pracy zespołowej nad aplikacjami — dzięki temu łatwiej zlokalizować problem czy zrozumieć/zauważyć sposób jego powstawania. I o ile zasady clean code są (mamy nadzieję) Ci dobrze znane, o tyle czytelność w przypadku zależności projektu niestety nie jest często spotykaną praktyką. W tym wypadku dobrym standardem powinny być trzy proste zasady:
- zależności w pliku pom.xml są ułożone alfabetycznie — pozwala to szybko sprawdzić, czy określona zależność jest dodana do projektu czy nie oraz w jakiej wersji
- w miarę możliwości projekt korzysta z dependencyManagement lub co najmniej z używania properties do określania wersji — dzięki temu unikniemy sytuacji, w których zależności z tej samej grupy (np. moduły Springa) są importowane w różnych, potencjalnie niezgodnych, wersjach
- wszystkie używane zależności powinny być deklarowane, a te, które nie są już używane powinny być usuwane z pliku POM — to najmniej oczywista zasada z powyższych — polega ona na tym, że korzystając z klasy pochodzącej z biblioteki lub zależności, musimy wskazać tą zależność jawnie w pliku pom.xml (innymi słowy, nie możemy używać zależności, które istnieją w projekcie tylko poprzez inne zależności; jest to dobra praktyka z 2 powodów — przede wszystkim pozwala kontrolować wersje zależności, których używamy, a także zabezpiecza nas przed zmianami w drzewie zależności które mogą spowodować problemy z budowaniem się projektu
Możemy w tym celu wykorzystać kilka pluginów. Pierwszy z nich to maven-dependency-plugin oraz jego cel analyze. Plugin ten analizuje zależności, jakie mamy zadeklarowane w projekcie oraz te, w których są klasy bezpośrednio przez nas używane. W przypadku rozbieżności informuje o tym w postaci warningów. Możemy (i w naszym przypadku tak zrobimy) skonfigurować go tak, że każdy znaleziony problem skutkuje błędem w budowaniu. Do naszego pliku pom.xml dodajmy następujący kod:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-dependency-plugin</artifactId>
<configuration>
<skip>${skip.dependency.analysis}</skip>
<outputXML>true</outputXML>
<failOnWarning>true</failOnWarning>
<ignoreNonCompile>true</ignoreNonCompile>
</configuration>
<executions>
<execution>
<id>analyze</id>
<goals>
<goal>analyze-only</goal>
</goals>
</execution>
</executions>
</plugin>Dodanie tej konfiguracji przy pierwszym buildzie zwróci najprawdopodobniej sporo problemów i uwag. Warto jednak poświęcić chwilę na jego konfigurację, aby pilnował nas w przyszłości ;)
Kolejny z przydatnych pluginów to sortpom, który można znaleźć na GitHubie.
Plugin ten pozwala na uporządkowanie pliku POM, sortując jego elementy, wyrównując wcięcia itp. Aby automatycznie sformatować nasz plik pom.xml wystarczy wywołać polecenie:
mvn com.github.ekryd.sortpom:sortpom-maven-plugin:sortWarto wykonać to polecenie i jego wynik dodać do repozytorium jako osobny commit — liczba zmian najprawdopodobniej będzie spora, dlatego dodanie ich razem z innymi zmianami mogłoby je ‘schować’ podczas PR. Po posortowaniu pliku pom.xml możemy dodać konfigurację, która będzie sprawdzała czy plik ten nadal jest posortowany i poprawnie sformatowany, w tym celu do sekcji <build> dodajemy kolejną konfigurację pluginu:
<plugin>
<groupId>com.github.ekryd.sortpom</groupId>
<artifactId>sortpom-maven-plugin</artifactId>
<version>2.8.0</version>
<executions>
<execution>
<id>sortpom</id>
<goals>
<goal>verify</goal>
</goals>
</execution>
</executions>
<configuration>
<keepBlankLines>true</keepBlankLines>
<verifyFail>Stop</verifyFail>
</configuration>
</plugin>Oczywiście możliwości konfiguracji jest więcej — ich opis znajdziesz w dokumentacji pluginu. Możliwe jest także automatyczne sortowanie zamiast weryfikacji w czasie budowania — w tym celu wystarczy usunąć linijkę <verifyFail>Stop</verifyFail>. Może to jednak prowadzić do formatowania niezgodnego z naszymi oczekiwaniami (np. usunięcie linii, zmiana względnej lokalizacji komentarzy itp) — dlatego bezpieczniej jest manualnie zweryfikować wyniki automatycznego poprawiania.
Dodatkowe sprawdzenia
Czasem zdarza się, że projekt ma specjalne wymagania — np. konkretnej wersji JDK, systemu operacyjnego lub innych czynników. W takim przypadku pomocny może być Maven enforcer plugin — pozwala sprawdzać parametry środowiska, zależności pod kątem niedozwolonych wersji/artefaktów, jak też zastosować własne reguły. W tym projekcie nie będziemy z niego korzystać, ale warto wiedzieć o jego istnieniu.
Listę elementów możliwych do sprawdzenia ‘od ręki’ znajdziesz oczywiście w dokumentacji.
Automatyzujemy kontrolę jakości — Checkstyle, PMD, SpotBugs (FindBugs)
Kolejnym krokiem jest sprawdzenie (oraz wymuszenie) stylu naszego kodu. W tej kategorii na szczególną uwagę zasługują trzy narzędzia:
- Checkstyle — pozwala sprawdzić nasz kod pod względem zgodności z przyjętymi zasadami stylu. O ile w Twojej organizacji / projekcie nie istnieją specyficzne zasady, warto skorzystać z wcześniej przygotowanych (np. Google style guide). O tym, czym jest Checkstyle oraz jak go skonfigurować, pisaliśmy w osobnym poście.
- SpotBugs (kontynuacja FindBugs, w przypadku którego zaprzestano rozwoju) — sprawdza kod pod kątem potencjalnych błędów (niezainicjowane zmienne, niezamknięte zasoby itp). O FindBugs (który jest bazą dla SpotBugs i póki co jest w większości kompatybilny pod kątem konfiguracji i funkcji) także pisaliśmy w osobnym wpisie.
- PMD/CPD — PMD jest narzędziem podobnym do FindBugs (skupia się na statycznej analizie kodu w celu znalezienia potencjalnych problemów), poszukiwane problemy różnią się jednak, więc warto korzystać z obu. CPD z kolei jest ciekawym narzędziem, ponieważ wyszukuje fragmenty kodu skopiowane w różnych miejscach. Dzięki temu wymusza wyciągnięcie wspólnego kodu do osobnych metod, co znacznie pomaga w zwiększeniu czytelności kodu
Wszystkie te narzędzia konfigurujemy w pliku pom.xml jako pluginy. Bazowa konfiguracja dla naszego projektu wyglądać będzie następująco:
<plugins>
...
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-checkstyle-plugin</artifactId>
<version>2.17</version>
<executions>
<execution>
<id>validate</id>
<phase>validate</phase>
<goals>
<goal>check</goal>
</goals>
<configuration>
<configLocation>google_checks.xml</configLocation><!-- używamy domyślnych reguł wg Google -->
<encoding>UTF-8</encoding>
<consoleOutput>true</consoleOutput>
<failsOnError>true</failsOnError>
<failOnViolation>true</failOnViolation>
<violationSeverity>warning</violationSeverity>
<linkXRef>false</linkXRef>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>com.github.spotbugs</groupId>
<artifactId>spotbugs-maven-plugin</artifactId>
<version>3.1.3</version>
<configuration>
<effort>Max</effort>
<threshold>Low</threshold>
<xmlOutput>true</xmlOutput>
</configuration>
<executions>
<execution>
<goals>
<goal>check</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-pmd-plugin</artifactId>
<version>3.8</version>
<executions>
<execution>
<id>pmd-pmd</id>
<goals>
<goal>check</goal>
</goals>
<configuration>
<excludeFromFailureFile>src/main/resources/exclude-pmd.properties</excludeFromFailureFile>
</configuration>
</execution>
<execution>
<id>pmd-cpd</id>
<goals>
<goal>cpd-check</goal>
</goals>
<configuration>
<excludeFromFailureFile>src/main/resources/exclude-cpd.properties</excludeFromFailureFile>
</configuration>
</execution>
</executions>
</plugin>
</plugins>Konfigurujemy środowisko CI
Uwaga! W tej sekcji omawiamy konfigurację na przykładzie Circle CI, ponieważ narzędzie to jest intuicyjne w użyciu i w pakiecie bezpłatnym można budować prywatne projekty. Jeśli z jakiegoś powodu nie jest to narzędzie dla Ciebie, lub po prostu chcesz spróbować innych narzędzi, na końcu tej sekcji znajdziesz kilka alternatyw — większość narzędzi typu SaaS jest bezpłatna dla projektów Open Source.
W przypadku środowiska CI mamy do wyboru dwie ścieżki — instalacje na własnym serwerze/infrastrukturze lub skorzystanie z narzędzia dostępnego w chmurze. W naszym wypadku wybierzemy opcję drugą — jest to zdecydowanie wygodniejsze dla małych projektów oraz także tańsze (dzięki bezpłatnym opcjom oferowanym przez różnych dostawców). W naszym projekcie skorzystamy z narzędzia CircleCI.
Pierwszym krokiem jest oczywiście rejestracja — możemy utworzyć nowe konto za pomocą loginu i hasła lub korzystając z integracji z Google czy GitHubem. Polecamy szczególnie integrację z GitHubem, ponieważ pozwoli to nam skonfigurować cały proces niemalże automatycznie.

Rejestracja za pomocą konta GitHub
Integrując się z Twoim kontem GitHub zostaniesz poproszona o akceptacje uprawnień:
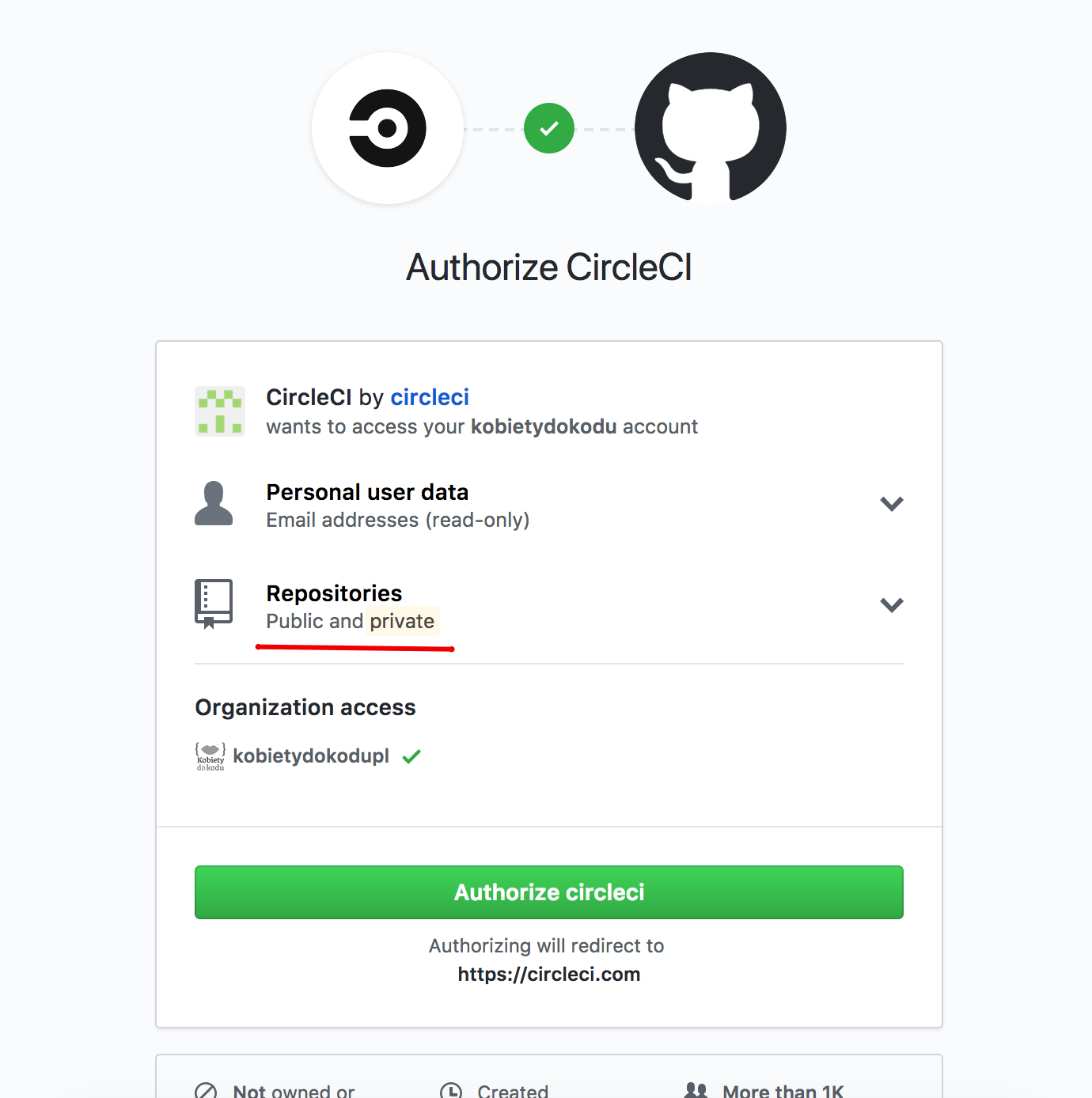
GitHub — akceptacja uprawnień dla CircleCI podczas rejestracji
Jakkolwiek byśmy nie utworzyli konta, po zalogowaniu się system przeniesie nas na główny ekran:
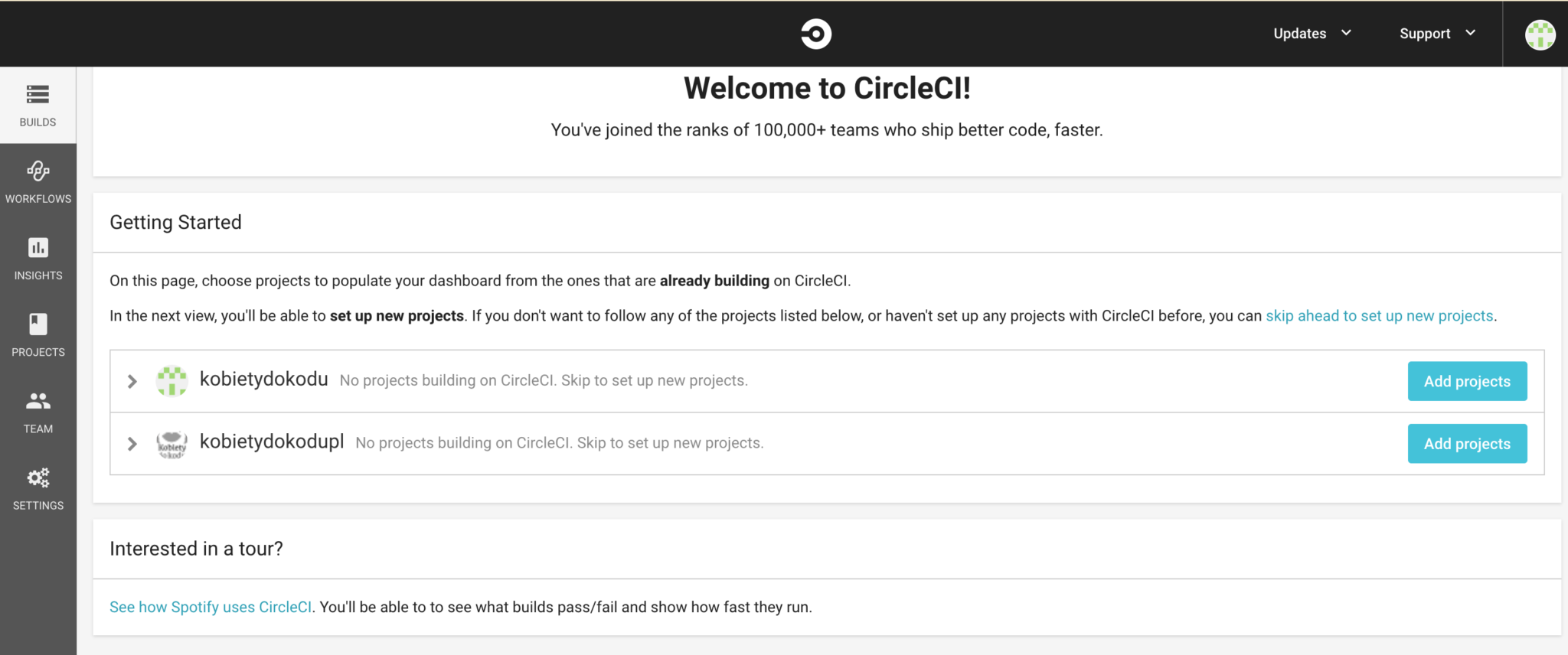
Główny ekran po pierwszym logowaniu do CircleCI
Widzimy tutaj listę organizacji, do których należymy. Najczęściej będzie to tylko jedna pozycja — Twoja nazwa użytkownika. W naszym przypadku mamy zarówno nazwę użytkownika (kobietydokodu) jak i organizację (kobietydokodupl). Przy opcji, która nas interesuje wybieramy ‘Add projects’ (jeśli później będziesz chciała skonfigurować dodatkowe repozytoria oczywiście jest to możliwe). Powinnaś zobaczyć listę dostępnych repozytoriów:
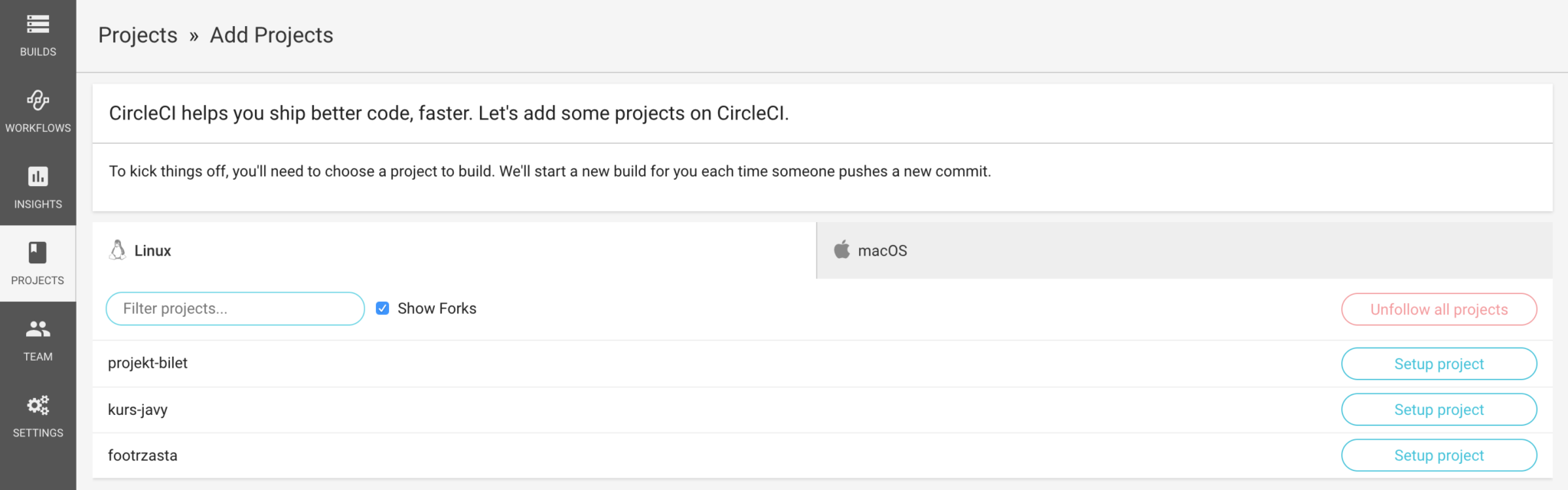
List repozytoriów w ramach organizacji
Tutaj wybieramy już konkretne repozytorium, które chcemy skonfigurować i klikamy w ‘Setup project’ w odpowiednim wierszu. Aplikacja przenosi nas do ustawień projektu:
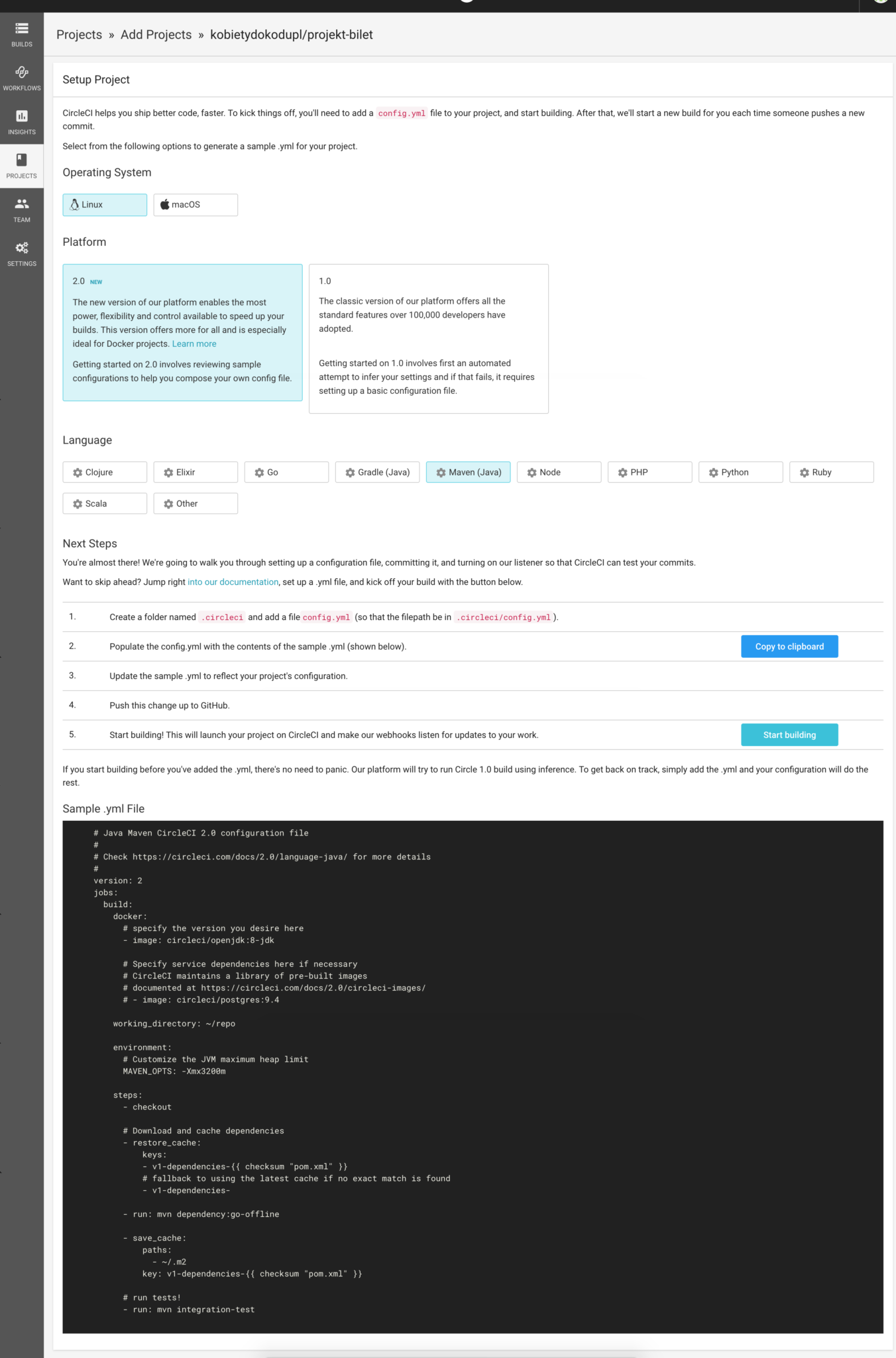
Ekran konfiguracji projektu
Jedynym ustawieniem, które musimy zmienić w naszym przypadku to przełączenie typu projektu (sekcja ‘Language’) na ‘Maven (Java)’ (domyślnie wybrany jest Gradle). Pozostałe ustawienia możemy pozostawić bez zmian.
Zwróć uwagę na listing na samym dole — zawiera on podstawową konfigurację którą należy skopiować i umieścić w pliku .circleci/config.yaml (tą samą konfigurację można znaleźć pod adresem https://circleci.com/docs/2.0/language-java/#sample-configuration). Bez niej nasza aplikacja także zostanie zbudowana, ale ten plik pozwoli nam na dokładniejsze dopasowanie procesu do naszych potrzeb w przyszłości. Na koniec klikamy ‘Start building’ aby rozpocząć pierwszy build projektu.
Aplikacja przekieruje nas na ekran builda — będziemy mogli na bieżąco śledzić postęp a także przejrzeć informacje o błędach, jeśli takie się pojawią. Zachęcamy do ‘przeklikania’ się przez interfejs — teoretycznie po skonfigurowaniu projektu nie będziemy wracać do tego narzędzia za często, w praktyce warto mieć choćby minimalne obycie z interfejsem i dostępnymi opcjami na wszelki wypadek ;)
Uwaga! Jako że domyślne środowisko dla projektu wykorzystuje system Linux do budowania projektu, za pierwszym razem nasz build zwróci błąd. Aby go rozwiązać, musimy dodać do naszego pliku pom.xml wersję testowej bazy danych dla systemu linux:
<dependency>
<groupId>ch.vorburger.mariaDB4j</groupId>
<artifactId>mariaDB4j-db-linux64</artifactId>
<version>10.1.13</version>
<scope>provided</scope>
</dependency>Konfigurujemy status badge
Jednym z dodatków, które oferuje CircleCI jest możliwość wstawiania ‘badge’ ze statusem buildu. O ile w przypadku projektu, który rozwijamy samodzielnie (lub w małym zespole) ma to ograniczoną przydatność (w przypadku problemów z buildem i tak otrzymamy powiadomienie mailowe), o tyle w przypadku projektów publicznych pozwala to innym osobom szybko zorientować się czy projekt jest w stanie nadającym się do sklonowania/wykorzystania/rozwoju czy nie. Dodanie badge jest bardzo proste, przede wszystkim musimy wygenerować token API dla projektu.
Podsumowanie tokenów API dla projektu
W tym celu w widoku ‘API Permissions’ wybieramy opcję ‘Create token’:
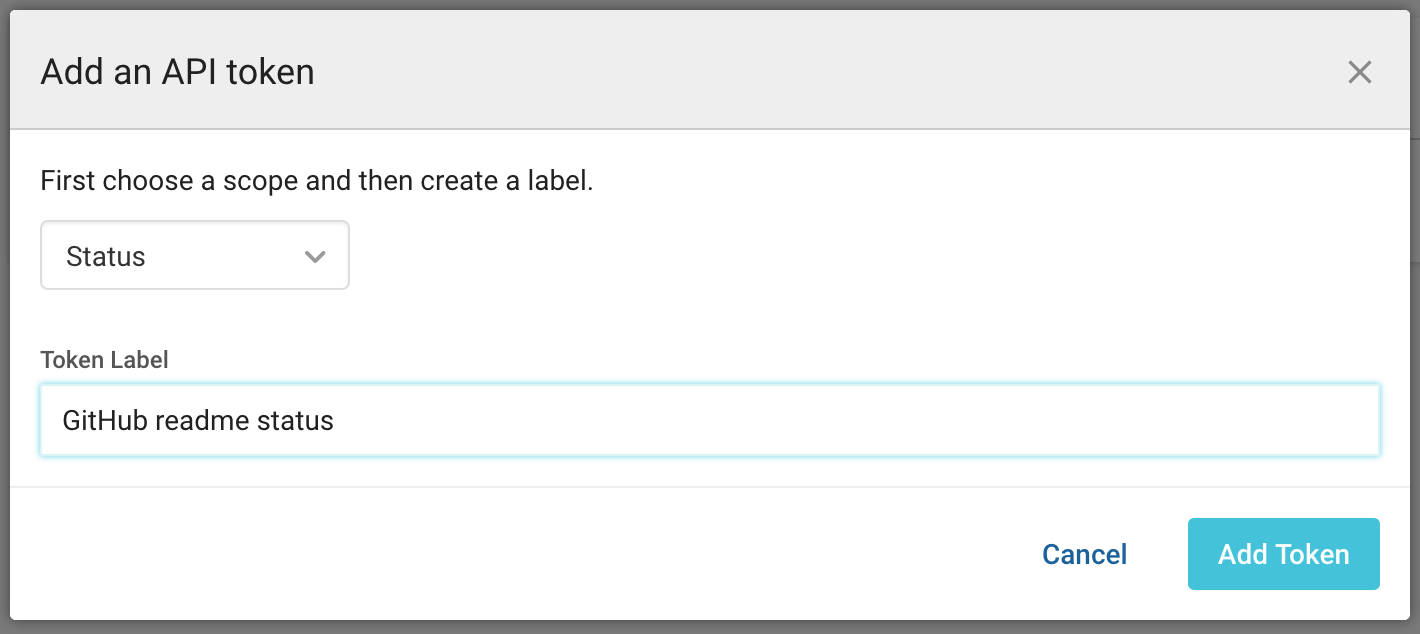
Widok dodawania tokenu API
A następnie wybieramy nazwę dla naszego tokenu (nazwa może być dowolna i służy tylko dla nas do łatwiejszej identyfikacji tokenu w przyszłości). W polu ‘scope’ wybieramy opcję ‘Status’ i klikamy ‘Add token’.
Następnie przechodzimy na zakładkę ‘Status badge’, wybieramy branch ‘master’ oraz nasz nowo utworzony token:

Generowanie badge ze statusem projektu
W okienku na dole pojawi się kod markdown, który możemy następnie skopiować do naszego pliku README.md .
Alternatywne narzędzia
Oczywiście poza omawianymi powyżej narzędziami istnieje wiele innych, które spełniają podobne funkcje. Często różnią się głównie interfejsem użytkownika, ceną i sposobem konfiguracji — funkcjonalnie większość narzędzi pozwala na mniej więcej to samo. Pokazane przez nas narzędzia wcale nie muszą być najlepsze czy najefektywniejsze dla Twojego projektu — zachęcamy do eksperymentowania z innymi platformami i wybrania takiej, która jest dla Ciebie najlepsza. Poniżej bardzo skrótowa lista narzędzi, które znamy — jeśli znasz i polecasz inne, zostaw linka w komentarzu!
Hosting projektu:
CI / build system:
- CircleCI
- Travis CI
- AWS CodeBuild, AWS Code Pipeline,
- Jenkins / Hudson (wymagany własny hosting)
Jak sama widzisz, opcji jest mnóstwo (a to z pewnością nie wszystkie dostępne możliwości) — niestety nie jesteśmy w stanie opisać konfiguracji każdej z nich, ale najczęściej dokumentacja tych narzędzi jest bardzo dokładna i samodzielna konfiguracja nie powinna stanowić problemu. Wiele z nich ma także aktywne społeczności, które chętnie pomogą z potencjalnymi problemami.
Jeśli zastanawiasz się, która z nich jest najlepsza, to niestety nie ma jednej ‘najlepszej’ platformy. Koncentrują się one na różnych rzeczach, więc w zależności od projektu, umiejętności i kompetencji zespołu oraz budżetu projektu rozwiązania te będą w innym stopniu dopasowane lub nie.
Podsumowanie
Mam nadzieję, że przekonaliśmy Cię, że czas poświęcony na konfiguracje i automatyzację procesu nie jest czasem straconym :) Choć czasem może być trudno przekonać osoby zarządzające na spędzenie kilku dni bez dostarczania dodatkowej funkcjonalności, włożony wysiłek z pewnością zwróci się bardzo szybko.
Kod źródłowy


Kody źródłowe są dostępne w serwisie GitHub — użyj przycisków po prawej aby pobrać lub przejrzeć kod do tego modułu. Jeśli masz wątpliwości, jak posługiwać się Git’em, instrukcje i linki znajdziesz w naszym wpisie na temat Git’a.

Jeśli uważasz powyższą lekcję za przydatną, mamy małą prośbę: polub nasz fanpage. Dzięki temu będziesz zawsze na bieżąco z nowymi treściami na blogu ( i oczywiście, z nowymi częściami kursu Javy). Dzięki!
